POOL、PG、CRUSH
POOL 存储池
https://docs.ceph.com/en/latest/rados/operations/pools/#rados-pools
存储池概述
- RADOS存储集群提供的基础存储服务需要由"存储池(pool)“分割为逻辑存储区域,此类的逻辑区域亦是对象数据的名称空间
- 实践中,管理员可以为特定应用程序存储不同类型数据的需求分别创建专用的存储池,例如rbd存储池、rgw存储池等,也可以为某个项目或某个用户创建专有的存储池
- 存储池还可以再进一步细分为一至多个名称空间(namespace)
- 客户端(包括rbd和rgw等)存取数据时,需要事先指定存储池名称、用户名和密钥等信息完成认证,而后将一直维持与其指定的存储池的连接,于是也可以把存储池看作是客户端的IO接口
存储池类型
副本池(replicated)
- 把每个对象在集群中存储为多个副本,其中存储于主OSD的为主副本,副本数量在创建存储池时由管理员指定;此为默认的存储池类型;
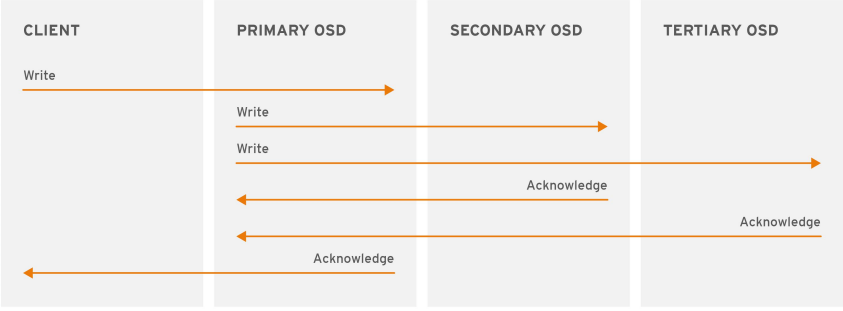
副本池 IO
- 将一个数据对象存储为多副本
- 写入操作时,Ceph客户端使用CRUSH算法来计算对象的PG ID和Primary OSD
- 主OSD根据设定的副本数、对象的名称、存储池名称和集群运行图(Cluster Map)计算出PG的各辅助OSD,而后由主OSD将数据同步给这些辅助OSD
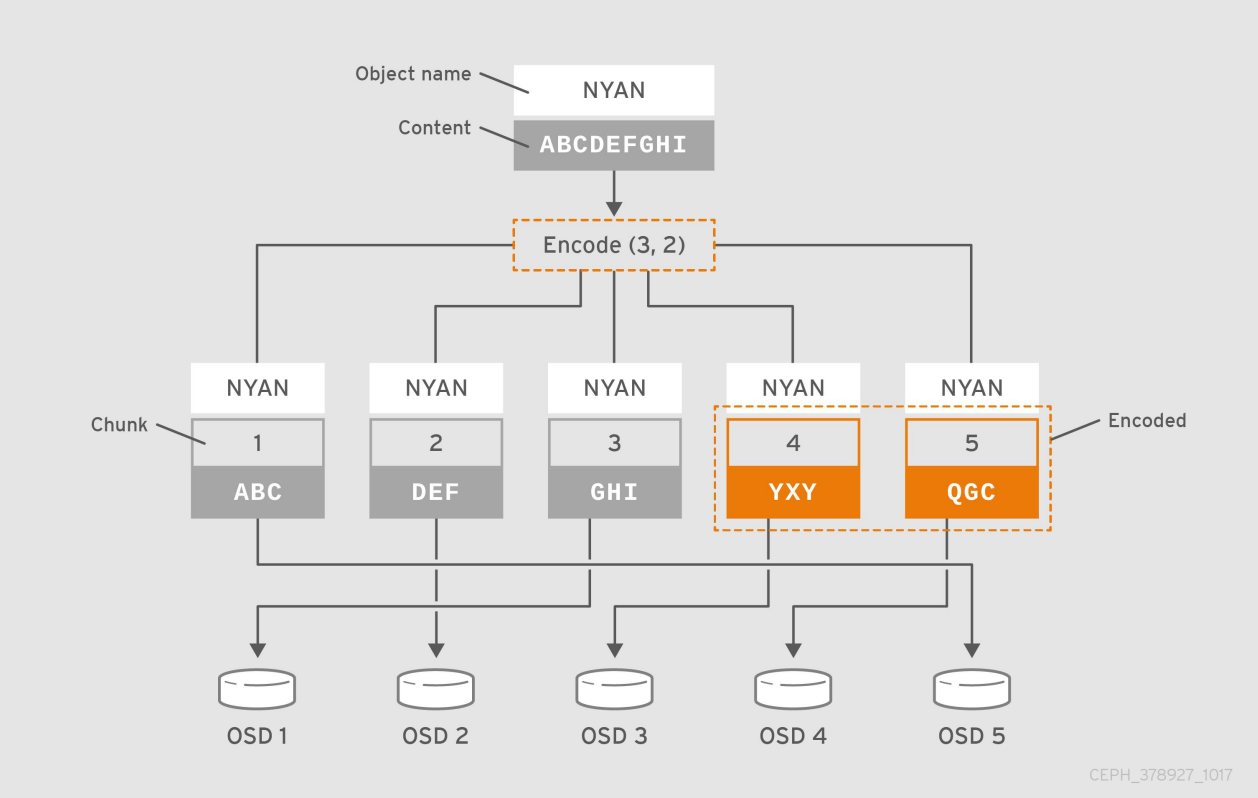
纠删码池(erasure code)
- 把各对象存储为 N=K+M 个块,其中,K为数据块数量,M为编码块数量,因此存储池的尺寸为 K+M ;
纠删码池IO
- 纠删码是一种前向纠错(FEC)代码
- 通过将K块的数据转换为N块,假设N=K+M,则其中的M代表纠删码算法添加的额外或冗余的块数量以提供冗余机制(即编码块),而N则表示在纠删码编码之后要创建的块的总数,其可以故障的总块数为M(即N-K)个
- 类似于 RAID 5
- 纠删码池减少了确保数据持久性所需的磁盘空间量,但计算量上却比副本存储池要更贵一些
- RGW可以使用纠删码存储池,但RBD不支持
举例:
- 例如,把包含数据“ABCDEFGHI”的对象NYAN保存到存储池中时,假设纠删码算法会将内容分割为三个数据块:第一个包含“ABC”,第二个为”DEF“,最后一个为”GHI“,并为这三个数据块额外创建两个编码块:第四个”YXY“和第五个”GQC“
- 在有着两个编码块配置的存储池中,它允许最多两个OSD不可用而不影响数据的可用性。假设,在某个时刻OSD 1和OSD 3因故无法正常响应客户端请求,这意味着客户端仅能读取到”ABC“、”DEF“和”QGC“,此时纠删编码算法会通过计算重那家出”GHI“和”YXY“
副本池和纠删码池对比
- 副本池更占用空间,但读性能更好
- 纠删码池占用空间较小,但读性能较差(因为需要更多的cpu进行计算)
存储池相关参数
存储池至少设置以下参数:
- 对象的所有权/访问权
- 归置组的数量
- 要使用的 CRUSH 规则(CRUSH 是一种算法,详情百度吧)
存储池相关命令
- ceph 、rados 命令都可以对存储池进行管理,但rados命令更加底层。
- 存储的常用管理操作包括列出、创建、重命名和删除等操作,常用相关的工具都是
ceph osd pool的子命令,包括ls、create、rename和rm等
创建存储池
创建副本型存储池
ceph osd pool create <poolname> <pg-num> [pgp-num] [replicated] [crush-rule-name] [expected-num-objects]- replicated 表示副本池,也是默认值,因此可不指定
范例:
# 创建一个名为mypool的存储池,设定其PG数量为16个
# ceph osd pool create mypool 16
pool 'mypool' created创建纠删码型存储池
ceph osd pool create <poolname> <pg-num> [pgp-num] erasure [erasure-code-profile] [crush-rule-name] [expected-num-objects]- erasure 表示纠删码池,需显示指定
范例:
- 删码型存储池并不常用
上述选项说明
pool-name # 存储池名称,在一个RADOS存储集群上必须具有唯一性;
pg-num # 当前存储池中的PG数量,合理的PG数量对于存储池的数据分布及性能表现来说至关重要;
pgp-num # 用于归置的PG数量,其值应该等于PG的数量
replicated|erasure # 存储池类型;副本存储池需更多原始存储空间,但已实现Ceph支持的所有操作,而纠删码存储池所需原始存储空间较少,但目前仅实现了Ceph的部分操作
crush-ruleset-name # 此存储池所用的CRUSH规则集的名称,不过,引用的规则集必须事先存在列出所有存储池
# ceph osd pool ls
mypool
# 更详细的信息
# ceph osd pool ls detail
pool 1 'mypool' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 16 pgp_num 16 last_change 30 flags hashpspool stripe_width 0
---
# rados lspools
mypool打印存储池状态
# 打印所有存储池的状态
# ceph osd pool stats
pool mypool id 1
nothing is going on
pool rbddata id 2
nothing is going on
pool .rgw.root id 3
nothing is going on
...
# 打印指定存储池的状态
# ceph osd pool stats mypool
pool mypool id 1
nothing is going on查看存储池用量
# ceph df
GLOBAL: # 存储量概览
# SIZE :集群的整体存储容量
# AVAIL :集群中可以使用的可用空间容量
# RAW USED :已用的原始存储量
# % RAW USED :已用的原始存储量百分比。将此数字与 full ratio 和 near full ratio搭配使用,可确保您不会用完集群的容量
SIZE AVAIL RAW USED %RAW USED
600 GiB 597 GiB 3.0 GiB 0.50
POOLS: # 存储池列表和每个存储池的理论用量,但出不反映副本、克隆数据或快照
NAME ID USED %USED MAX AVAIL OBJECTS
mypool 1 0 B 0 189 GiB 0
rbddata 2 134 B 0 189 GiB 5
.rgw.root 3 1.1 KiB 0 189 GiB 4
default.rgw.control 4 0 B 0 189 GiB 8
default.rgw.meta 5 0 B 0 189 GiB 0
default.rgw.log 6 0 B 0 189 GiB 175
cephfs-metadata 7 2.2 KiB 0 189 GiB 22
cephfs-data 8 0 B 0 189 GiB 0
# 更详细的信息
# ceph df detail
...查看数据对象
# 获取到存储池中数据对象的具体位置信息
# ceph osd map mypool issue
osdmap e32 pool 'mypool' (1) object 'issue' -> pg 1.651f88da (1.a) -> up ([2,1,0], p2) acting ([2,1,0], p2)向存储池上传数据对象
而后即可将测试文件上传至存储池中,例如下面的rados put命令将 /etc/issue 文件上传至mypool 存储池,对象名称依然保留为文件名 issue,而 rados ls命令则可以列出指定存储池中的数据对象。
# rados put issue /etc/issue --pool=mypool
# rados ls --pool=mypool
issue设置存储池配额
- Ceph支持为存储池设置可存储对象的最大数量(max_objects)和可占用的最大空间( max_bytes)两个纬度的配额
- 命令格式:
ceph osd pool set-quota <pool-name> max_objects|max_bytes <val>
获取存储池配额的相关信息
- 命令:
ceph osd pool get-quota <pool-name>
配置存储池参数
- 存储池的诸多配置属性保存于配置参数中
- 获取配置:
ceph osd pool get <pool-name> <size | min_size | pg_num | pgp_num |...> - 设定配置:
ceph osd pool set <pool-name> <key> <value>
- 获取配置:
可用的配置参数
size # 存储池中的对象副本数;
min_size # I/O所需要的最小副本数;
pg_num # 存储池的PG数量;
pgp_num # 计算数据归置时要使用的PG的有效数量;
crush_ruleset # 用于在集群中映射对象归置的规则组;
nodelete # 控制是否可删除存储池;
nopgchange # 控制是否可更改存储池的pg_num和pgp_num;
nosizechange # 控制是否可更改存储池的大小;
noscrub和nodeep-scrub # 控制是否可整理或深层整理存储池以解决临时高I/O负载的问题
scrub_min_interval # 集群负载较低时整理存储池的最小时间间隔;默认值为0,表示其取值来自于配置文件中的osd_scrub_min_interval参数;
scrub_max_interval # 整理存储池的最大时间间隔;默认值为0,表示其取值来自于配置文件中的osd_scrub_max_interval参数;
deep_scrub_interval # 深层整理存储池的间隔;默认值为0,表示其取值来自于配置文件中的osd_deep_scrub参数;存储池快照
- 存储池快照是指整个存储池的状态快照
- 通过存储池快照,可以保留存储池状态的历史
- 创建存储池快照可能需要大量存储空间,具体取决于存储池的大小
创建存储池快照
ceph osd pool mksnap <pool-name> <snap-name>- 或
rados -p <pool-name> mksnap <snap-name>
列出存储池的快照
rados -p <pool-name> lssnap
回滚存储池至指定的快照
rados -p <pool-name> rollback <snap-name>
删除存储池快照
ceph osd pool rmsnap <pool-name> <snap-name>- 或
rados -p <pool-name> rmsnap <snap-name>
数据压缩
BlueStore存储引擎提供即时数据压缩,以节省磁盘空间
启用压缩
ceph osd pool set <pool-name> compression_algorithm snappy- 压缩算法有none、zlib、lz4、zstd和snappy等几种,默认为snappy;
- zstd有较好的压缩比,但比较消耗CPU;
- lz4和snappy对CPU占用比例较低;
- 不建议使用zlib;
压缩模式
ceph osd pool set <pool-name> compression_mode aggressive- none、aggressive、passive和force,默认值为none;
- none:不压缩
- passive:若提示COMPRESSIBLE,则压缩
- aggressive:除非提示INCOMPRESSIBLE,否则就压缩;
- force:始终压缩
其它压缩参数
- compression_required_ratio:指定压缩比,取值格式为双精度浮点型,其值为SIZE_COMPRESSED/SIZE_ORIGINAL,即压缩后的大小与原始内容大小的比值,默认为.875;
- compression_max_blob_size:压缩对象的最大体积,无符号整数型数值,默认为0;
- compression_min_blob_size:压缩对象的最小体积,无符号整数型数值,默认为0
全局压缩选项
- 可在ceph配置文件中设置压缩属性,它将对所有的存储池生效
- 可设置的相关参数如下:
- bluestore_compression_algorithm
- bluestore_compression_mode
- bluestore_compression_required_ratio
- bluestore_compression_min_blob_size
- bluestore_compression_max_blob_size
- bluestore_compression_min_blob_size_ssd
- bluestore_compression_max_blob_size_ssd
- bluestore_compression_min_blob_size_hdd
- bluestore_compression_max_blob_size_hdd
重命名存储池
ceph osd pool rename old-name new-name
删除存储池中的数据对象
# rados rm issue --pool=mypool删除存储池
-
删除存储池命令存在数据丢失的风险,Ceph于是默认禁止此类操作。管理员需要在ceph.conf配置文件中启用支持删除存储池的操作后(或使用下面的方法临时设置),方可使用类似如下命令删除存储池。
-
意外删除存储池会导致数据丢失,因此 Ceph 实施了两个机制来防止删除存储 池,要删除存储池,必须先禁用这两个机制
- 第一个机制是NODELETE标志,其值需要为false,默认也是false
- 查看命令:
ceph osd pool get pool-name nodelete - 修改命令:
ceph osd pool set pool-name nodelete false
- 查看命令:
- 第二个机制是集群范围的配置参数mon allow pool delete,其默认值为 “false” ,这表示默认不能删除存储池,临时设定的方法如下
ceph tell mon.* injectargs --mon-allow-pool-delete={true|false}- 建议删除之前将其值设置为true,删除完成后再改为false
- 第一个机制是NODELETE标志,其值需要为false,默认也是false
-
删除命令:
ceph osd pool rm pool-name pool-name --yes-i-really-really- mean-it
范例:
# 查看nodelete是否为false
# ceph osd pool get rbddata nodelete
nodelete: false
# 取消不允许删除存储池
# ceph tell mon.* injectargs --mon-allow-pool-delete=true
mon.stor01: injectargs:mon_allow_pool_delete = 'true'
mon.stor02: injectargs:mon_allow_pool_delete = 'true'
mon.stor03: injectargs:mon_allow_pool_delete = 'true'
# 删除存储池
# ceph osd pool rm rbddata rbddata --yes-i-really-really-mean-it
pool 'rbddata' removed
# 设置回不允许删除存储池
# ceph tell mon.* injectargs --mon-allow-pool-delete=false
mon.stor01: injectargs:mon_allow_pool_delete = 'false'
mon.stor02: injectargs:mon_allow_pool_delete = 'false'
mon.stor03: injectargs:mon_allow_pool_delete = 'false' 纠删码存储池
- 空间利用率高:K/N,K为数据块量,N为加上编码块量的总块数;
创建纠删码池
ceph osd pool create <pool-name> <pg-num> <pgp-num> erasure [erasure-code-profile] [crush-rule-name] [expected-num-objects]- 未指定要使用的纠删编码配置文件时,创建命令会为其自动创建一个,并在创建相关的CRUSH规则集时使用到它
- 默认配置文件自动定义k=2和m=1,这意味着Ceph将通过三个OSD扩展对象数据,并且可以丢失其中一个OSD而不会丢失数据,因此,在冗余效果上,它相当于一个大小为2的副本池 ,不过,其存储空间有效利用率为2/3而非1/2
纠删码配置文件
列出纠删码配置文件
ceph osd erasure-code-profile ls
获取指定的配置文件的相关内容
ceph osd erasure-code-profile get default
自定义纠删码配置文件
-
ceph osd erasure-code-profile set <name> [<directory=directory>] [<plugin=plugin>] [<crush-device-class>] [<crush-failure-domain>] [<key=value> ...] [--force]-
directory:加载纠删码插件的目录路径,默认为/usr/lib/ceph/erasure-code;
-
plugin:用于生成及恢复纠删码块的插件名称,默认为jerasure;
-
crush-device-class:设备类别,例如hdd或ssd,默认为none,即无视类别;
-
crush-failure-domain:故障域,默认为host,支持使用的包括osd、host、rack、row和room等;
-
–force:强制覆盖现有的同名配置文件;
-
-
例如,如果所需的体系结构必须承受两个OSD的丢失,并且存储开销为40%
-
ceph osd erasure-code-profile set myprofile k=4 m=2 crush-failure-domain=os
纠删码插件
Ceph支持以插件方式加载使用的纠删编码插件,存储管理员可根据存储场景的需要优化选择合用的插件。目前,Ceph支持的插件包括如下三个:
- jerasure:最为通用的和灵活的纠删编码插件,它也是纠删码池默认使用的插件;不过,
- 任何一个OSD成员的丢失,都需要余下的所有成员OSD参与恢复过程;另外,使用此类插
- 件时,管理员还可以通过technique选项指定要使用的编码技术:
- • reed_sol_van:最灵活的编码技术,管理员仅需提供k和m参数即可;
- • cauchy_good:更快的编码技术,但需要小心设置PACKETSIZE参数;
- • reed_sol_r6_op、liberation、blaum_roth或liber8tion:仅支持使用m=2的编码技术,功能特性
- 类同于RAID 6;
- lrc:全称为Locally Repairable Erasure Code,即本地修复纠删码,除了默认的m个编码块之外,它会额外在本地创建指定数量(l)的奇偶校验块,从而在一个OSD丢失时,可以仅通过l个奇偶校验块完成恢复
- isa:仅支持运行在intel CPU之上的纠删编码插件,它支持reed_sol_van和cauchy两种技术
例如,下面的命令创建了一个使用lrc插件的配置文件LRCprofile,其本地奇偶校验块为3,故障域为osd
ceph osd erasure-code-profile set LRCprofile plugin=lrc k=4 m=2 l=3 crush-failure-domain=osd
PG 归置组
https://docs.ceph.com/en/latest/rados/operations/placement-groups/
https://docs.ceph.com/en/latest/architecture/#mapping-pgs-to-osds
归置组概述
- 归置组(Placement Group)是用于跨OSD将数据存储在某个存储池中的内部数据结构
- 在每个存储池都有许多归置组。
- 相对于存储池来说,PG是一个虚拟组件,它是对象映射到OSD时使用的虚拟层
- 出于规模伸缩及性能方面的考虑,Ceph将存储池细分为归置组,把每个单独的对象映射到归置组(CRUSH 算法的第一步),并将归置组分配给一个主OSD(CRUSH 算法的第二步)
- 因此每个对象都会对应一个PG
- 存储池由一系列的归置组组成,而CRUSH算法则根据集群运行图和集群状态,将各PG均匀、伪随机地分布到集群中的OSD之上
- 所谓伪随机指的是分布时随机,但读取时需按顺序读
- 若某OSD失败或需要对集群进行重新平衡,Ceph则移动或复制整个归置组而无需单独寻址每个对象
- 归置组在OSD守护进程和Ceph客户端之间生成了一个中间层,CRUSH算法负责将每个对象动态映射到一个归置组,然后再将每个归置组动态映射到一个或多个OSD守护进程,从而能够支持在新的OSD设备上线时动态进行数据重新平衡
数据存储过程
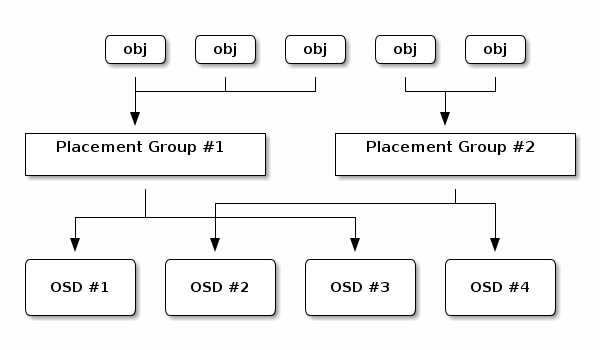
-
每个池都有多个 PG,当 Ceph 客户端存储对象时,会通过 CRUSH 算法将每个数据对象映射到一个 PG,最后CRUSH 算法可以将 PG 动态映射到OSD。
-
冗余性:
- 每个 PG 默认会分成三个分片,数据第一次会写入到主分片,而后数据会同步到副本分片,以实现将数据存储到不同的OSB当中,从而达到数据冗余的目的。
归置组计数
- 归置组的数量由管理员在创建存储池时指定,而后由CRUSH负责创建和使用
- 通常,PG的数量应该是数据的合理粒度的子集
- 例如,一个包含256个PG的存储池意味着每个PG包含大约1/256的存储池数据
- 当需要将PG从一个OSD移动到另一个OSD时,PG的数量会对性能产生影响
- PG数量过少,Ceph将不得不同时移动相当数量的数据,其产生的网络负载将对集群的正常性能输出产生负面影响
- 而在过多的PG数量场景中在移动极少量的数据时,Ceph将会占用过多的CPU和RAM,从而对集群的计算资源产生负面影响。
- 通常,PG的数量应该是数据的合理粒度的子集
- PG数量在群集分发数据和重新平衡时扮演着重要作用
- 在所有OSD之间进行数据持久存储及完成数据分布会需要较多的归置组,但是它们的数量应该减少到最大性能所需的最小数量值,以节省CPU和内存资源
- 一般说来,对于有着超过50个OSD的RADOS集群,建议每个OSD大约有50-100个PG以平衡资源使用,取得更好的数据持久性和数据分布,更大规模的集群中,每个OSD大约可持有100-200个PG
- 至于应该使用多少个PG,可通过下面的公式计算后,将其值以类似于四舍五入到最近的2的N次幂
(Total OSDs * PGPerOSD)/Replication factor => Total PGs
- 一个RADOS集群上可能会存在多个存储池,因此管理员还需要考虑所有存储池上的PG分布后每个OSD需要映射的PG数量
PG 数量计算器
归置组状态
PG当前的工作特性或工作进程所处的阶段,最为常见的状态应该为active+clean
Active
- 主 OSD 和各辅助 OSD 均处于就绪状态,可正常服务于客户端的IO请求
- 一般 Peering 操作过程完成后即会转入Active状态
Clean
- 主OSD和各辅助OSD均处于就绪状态,所有对象的副本数量均符合期望,并且PG的活动集和上行集是为同一组OSD
- 活动集(Acting Set):由PG当前的主OSD和所有的处于活动状态的辅助OSD组成,这组OSD负责执行此PG上数据对象的存取操作I/O
- 上行集(Up Set):根据CRUSH的工作方式,集群拓扑架构的变动将可能导致PG相应的OSD变动或扩展至其它的OSD之上,这个新的OSD集也称为PG的”上行集(Up Set)“,其映射到的新OSD集可能部分地与原有OSD集重合,也可能会完全不相干; 上行集OSD需要从当前的活动集OSD上复制数据对象,在所有对象同步完成后,上行集便成为新的活动集,而PG也将转为“活动(active)”状态
Peering
- 一个PG中的所有OSD必须就它们持有的数据对象状态达成一致,而”对等(Peering)“即为让其 OSD从不一致转为一致的过程
Degraded
- 在某OSD标记为”down“时,所有映射到此OSD的PG即转入“降级(degraded)”状态
- 此OSD重新启动并完成Peering操作后,PG将重新转回clean
- 一旦OSD标记为down的时间超过5分钟,它将被标记出集群,而后Ceph将对降级状态的PG启动恢复操作,直到所有因此而降级的PG重回clean状态
- 在其内部OSD上某对象不可用或悄然崩溃时,PG也会被标记为降级状态,直至对象从某个权威副本上正确恢复
Stale
- 每个OSD都要周期性地向RADOS集群中的监视器报告其作为主OSD所持有的所有PG的最新统计数 据,因任何原因导致某个主OSD无法正常向监视器发送此类报告,或者由其它OSD报告某个OSD已经down掉,则所有以此OSD为主OSD的PG将立即被标记为stale状态
Undersized
- PG中的副本数少于其存储池定义的个数时即转入undersized状态,恢复和回填操作在随后会启动以修复其副本数为期望值
Scrubbing
- 各OSD还需要周期性地检查其所持有的数据对象的完整性,以确保所有对等OSD上的数据一致; 处于此类检查过程中的PG便会被标记为scrubbing状态,这也通常被称作light scrubs、shallow scrubs或者simply scrubs;
- 另外,PG还偶尔需要进行deep scrubs检查以确保同一对象在相关的各OSD上能按位匹配,此时PG将处于scrubbing+deep状态;
Recovering
- 添加一个新的OSD至存储集群中或某OSD宕掉时,PG则有可能会被CRUSH重新映射进而将持有与此不同的OSD集,而这些处于内部数据同步过程中的PG则被标记为recovering状态;
Backfilling
- 新OSD加入存储集群后,Ceph则会进入数据重新均衡的状态,即一些数据对象会在进程后台从现有OSD移到新的OSD之上,此操作过程即为backfill;
归置组相关命令
- pool、rados 命令都可以对归置组进行管理,但rados命令更加底层。
打印所有PG
# ceph pg ls
...打印归置组状态
# 打印所有归置组的状态
# ceph pg stat
240 pgs: 240 active+clean; 3.5 KiB data, 3.0 GiB used, 597 GiB / 600 GiB avail
...CRUSH
CRUSH 概述
-
Controlled Replication Under Scalable Hashing
-
它是一种数据分布式算法,类似于一致性哈希算法,用于为RADOS存储集群控制数据分布
-
Ceph 客户端从 Ceph 监视器检索集群映射,并将对象写入池中。池size或副本的数量、CRUSH 规则和归置组的数量决定了 Ceph 将如何放置数据。
-
通过 CRUSH 算法,客户端可以准确计算在读取或写入特定对象时使用哪个 OSD。
-
Ceph 将数据作为对象存储在逻辑存储池中。使用 CRUSH算法,Ceph 计算出哪个归置组应该包含该对象,并进一步计算出哪个 Ceph OSD Daemon 应该存储该归置组。CRUSH 算法使 Ceph 存储集群能够动态扩展、重新平衡和恢复。
关于 CRUSH
- 把对象直接映射到OSD之上会导致二者之间的紧密耦合关系,在OSD设备变动时不可避免地对整个集群产生扰动
- 于是,Ceph将一个对象映射进RADOS集群的过程分为两步
- 首先是以一致性哈希算法将对象名称映射到PG
- 而后是将PG ID基于CRUSH算法映射到OSD
- 这两个过程都以“实时计算”的方式完成,而非传统的查表方式,从而有效规避了任何组件被“中心化”的可能性,使得集群规模扩展不再受限
- 这个实时计算操作用到的算法就是CRUSH
客户端IO的简要工作流程
执行对象的存取操作时,客户端需要输入的是对象标识和存储池名称
- 客户端需要在存储池中存储命名对象时,它将对象名称、对象名称的哈希码、存储池中的PG数量和存储池名称作为输入,而后由CRUSH计算出PG的ID及此PG的主OSD
- 通过将对象标识进行一致性哈希运算得到的哈希值与PG位图掩码进行”与“运算得到目标PG,从而得出目标PG的ID(pg_id),完成由Object至PG的映射
- 而后,CRUSH算法便将以此pg_id、CRUSH运行图和归置规则(Placement Rules)为输入参数再次进行计算,并输出一个确定且有序的目标存储向量列表(OSD列表),从而完 成从PG至OSD的映射
存取对象时,客户端从Ceph监视器检索出集群运行图,绑定到指定的存储池,并对存储池上PG内的对象执行IO操作
- 存储池的CRUSH规则集和PG的数量是决定Ceph如何放置数据的关键性因素
- 基于最新版本的集群运行图,客户端能够了解到集群中的所有监视器和OSD以及它们各自的当前状态
- 不过,客户端对目标对象的位置却一无所知
Ceph客户端使用以下步骤来计算PG ID
- 客户端输入存储池名称及对象名称,例如,pool = pool1以及object-id = obj1
- 获取对象名称并通过一致性哈希算法对其进行哈希运算,即hash(o),其中o为对象名称
- 将计算出的对象标识哈希码与PG位图掩码进行“与”运算获得目标PG的标识符,即PGID,例如1701
- 计算公式为pgid=func(hash(o)&m,r),其中,变量o是对象标识符,变量m是当前存储池中PG的位图掩码,变量r是指复制因子,用于确定目标PG中OSD数量
- CRUSH根据集群运行图计算出与目标PG对应的有序的OSD集合,并确定出其主OSD
- 客户端获取到存储池名称对应的数字标识,例如,存储池“pool1”的数字标识11
- 客户端将存储池的ID添加到PG ID,例如,11.1701
- 客户端通过直接与PG映射到的主OSD通信来执行诸如写入、读取或删除之类的对象操作