DQL
前言
SELECT 是 SQL 中用于从数据库中检索数据的语句。通过 SELECT 语句,可以从一个或多个表中选择特定列的数据,也可以使用不同的条件、排序和聚合函数对数据进行处理。
基本的 SELECT 语法如下:
SELECT column1, column2, ..., columnN
FROM table_name
WHERE condition;其中:
column1, column2, ..., columnN是要选择的列的名称。table_name是要检索数据的表的名称。WHERE condition是可选的条件,用于筛选满足特定条件的行。
例子:
SELECT first_name, last_name, salary
FROM employees
WHERE department = 'IT';在这个例子中,从 employees 表中选择了 first_name、last_name 和 salary 列的数据,且仅选择部门为 ‘IT’ 的员工。
SELECT 语句的其他一些常见子句和用法包括:
-
DISTINCT关键字:-
用于返回不重复的行。
-
例子:
SELECT DISTINCT department FROM employees;
-
-
聚合函数:
-
用于对数据进行聚合,如
COUNT、SUM、AVG、MIN、MAX等。 -
例子:
SELECT AVG(salary) FROM employees WHERE department = 'Sales';
-
-
ORDER BY子句:- 用于按指定列对结果进行排序。
- 例子:
SELECT first_name, last_name, hire_date FROM employees ORDER BY hire_date DESC;
-
LIMIT(或FETCH FIRST)子句:- 用于限制结果集的行数。
- 例子:
SELECT first_name, last_name FROM employees ORDER BY last_name LIMIT 10;
-
JOIN子句:- 用于联结多个表的数据。
- 例子:
SELECT employees.first_name, employees.last_name, departments.department_name FROM employees INNER JOIN departments ON employees.department_id = departments.department_id;
SELECT 语句是 SQL 中最常用的语句之一,通过灵活运用不同的子句和条件,可以满足各种复杂的数据检索需求。
SELECT 语法:
SELECT
[ALL | DISTINCT | DISTINCTROW ]
[HIGH_PRIORITY]
[STRAIGHT_JOIN]
[SQL_SMALL_RESULT] [SQL_BIG_RESULT] [SQL_BUFFER_RESULT]
[SQL_NO_CACHE] [SQL_CALC_FOUND_ROWS]
select_expr [, select_expr] ...
[into_option]
[FROM table_references
[PARTITION partition_list]]
[WHERE where_condition]
[GROUP BY {col_name | expr | position}, ... [WITH ROLLUP]]
[HAVING where_condition]
[WINDOW window_name AS (window_spec)
[, window_name AS (window_spec)] ...]
[ORDER BY {col_name | expr | position}
[ASC | DESC], ... [WITH ROLLUP]]
[LIMIT {[offset,] row_count | row_count OFFSET offset}]
[into_option]
[FOR {UPDATE | SHARE}
[OF tbl_name [, tbl_name] ...]
[NOWAIT | SKIP LOCKED]
| LOCK IN SHARE MODE]
#简单语法
SELECT 列 FROM teachers [where] [行]SELECT
算术操作符
+
mysql> SELECT name, age FROM teachers;
+---------------+-----+
| name | age |
+---------------+-----+
| Song Jiang | 45 |
| Zhang Sanfeng | 94 |
| Miejue Shitai | 77 |
| Lin Chaoying | 93 |
+---------------+-----+
## 所有年龄加10岁:
mysql> SELECT name, age+10 FROM teachers;
+---------------+--------+
| name | age+10 |
+---------------+--------+
| Song Jiang | 55 |
| Zhang Sanfeng | 104 |
| Miejue Shitai | 87 |
| Lin Chaoying | 103 |
+---------------+--------+-
*
/
%
聚合函数
- 用于对数据进行聚合,如
COUNT、SUM、AVG、MIN、MAX等。
COUNT
返回结果集中行的数量,可以用于整个表,也可以用于特定列或满足特定条件的行。
例子1:
-- 返回 teachers 表的总行数
SELECT COUNT(*)
FROM teachers;例子2:
COUNT 还可以用于计算满足特定条件的行数。例如,计算部门为 ‘IT’ 的员工数量:
SELECT COUNT(*)
FROM employees
WHERE department = 'IT';例子3:
COUNT 还可以与 DISTINCT 结合使用,以计算唯一值的数量。例如,计算不同部门的数量:
SELECT COUNT(DISTINCT department)
FROM employees;在这个例子中,返回了 employees 表中不同部门的数量。
注意事项:
COUNT 不会计算包含 NULL 值的列。如果要计算包含 NULL 值的列,可以使用 COUNT(*) 或 COUNT(column_name),而不是 COUNT(1)。
SELECT COUNT(*) -- 计算包含 NULL 的列
FROM table_name;
SELECT COUNT(column_name) -- 计算指定列中不为 NULL 的行数
FROM table_name;SUM
SUM 返回指定列的所有数值之和。这可以用于对数值型列进行汇总,例如工资、销售额等。
SELECT SUM(column_name)
FROM table_name
WHERE condition;column_name是要计算总和的列的名称。table_name是包含要计算总和的数据的表的名称。WHERE condition是可选的条件,用于筛选满足特定条件的行。
需要注意的是,SUM 仅对数值型列有效,对非数值型列的使用会导致错误。
例子1:
mysql> SELECT age FROM teachers;
+-----+
| age |
+-----+
| 45 |
| 94 |
| 77 |
| 93 |
+-----+
mysql> SELECT sum(age) FROM teachers;
+----------+
| sum(age) |
+----------+
| 309 |
+----------+例子2:
SELECT SUM(salary)
FROM employees
WHERE department = 'Sales';在这个例子中,返回了 employees 表中销售部门员工工资的总和。
例子3:
SUM 也可以用于计算多个列的总和,例如:
SELECT SUM(column1 + column2)
FROM table_name
WHERE condition;AVG
AVG 是 SQL 中用于计算表中列的平均值的聚合函数。AVG 返回指定列的所有数值的平均值。这可以用于对数值型列进行统计,例如计算平均工资、平均销售额等。
基本的 AVG 使用形式如下:
SELECT AVG(column_name)
FROM table_name
WHERE condition;其中:
column_name是要计算平均值的列的名称。table_name是包含要计算平均值的数据的表的名称。WHERE condition是可选的条件,用于筛选满足特定条件的行。
例子:
SELECT AVG(salary)
FROM employees
WHERE department = 'Sales';在这个例子中,返回了 employees 表中销售部门员工工资的平均值。
AVG 也可以用于计算多个列的平均值,例如:
SELECT AVG((column1 + column2) / 2)
FROM table_name
WHERE condition;需要注意的是,AVG 仅对数值型列有效,对非数值型列的使用会导致错误。在使用 AVG 之前,建议检查列的数据类型以确保其为数值类型。
与 SUM 类似,AVG 也可以与其他聚合函数结合使用,以计算多个统计指标。
总之,AVG 是在 SQL 查询中对数值型数据进行平均值计算的有用函数。
MIN
MIN 是 SQL 中用于计算表中列的最小值的聚合函数。MIN 返回指定列的所有数值中的最小值。这可以用于找到数值型列的最小值,例如查找最低工资、最早入职日期等。
基本的 MIN 使用形式如下:
SELECT MIN(column_name)
FROM table_name
WHERE condition;其中:
column_name是要计算最小值的列的名称。table_name是包含要计算最小值的数据的表的名称。WHERE condition是可选的条件,用于筛选满足特定条件的行。
例子:
SELECT MIN(salary)
FROM employees
WHERE department = 'IT';在这个例子中,返回了 employees 表中 IT 部门员工的最低工资。
MIN 也可以用于计算多个列的最小值,例如:
SELECT MIN(LEAST(column1, column2))
FROM table_name
WHERE condition;需要注意的是,MIN 仅对数值型列有效,对非数值型列的使用会导致错误。在使用 MIN 之前,建议检查列的数据类型以确保其为数值类型。
总之,MIN 是在 SQL 查询中找到数值型数据中最小值的有用函数。
MAX
MAX 是 SQL 中用于计算表中列的最大值的聚合函数。MAX 返回指定列的所有数值中的最大值。这可以用于找到数值型列的最大值,例如查找最高工资、最晚入职日期等。
基本的 MAX 使用形式如下:
SELECT MAX(column_name)
FROM table_name
WHERE condition;其中:
column_name是要计算最大值的列的名称。table_name是包含要计算最大值的数据的表的名称。WHERE condition是可选的条件,用于筛选满足特定条件的行。
例子:
SELECT MAX(salary)
FROM employees
WHERE department = 'Sales';在这个例子中,返回了 employees 表中销售部门员工的最高工资。
MAX 也可以用于计算多个列的最大值,例如:
SELECT MAX(GREATEST(column1, column2))
FROM table_name
WHERE condition;需要注意的是,MAX 仅对数值型列有效,对非数值型列的使用会导致错误。在使用 MAX 之前,建议检查列的数据类型以确保其为数值类型。
总之,MAX 是在 SQL 查询中找到数值型数据中最大值的有用函数。
字符串处理
CONCAT()
CONCAT(str1, str2, ...)连接字符串。
mysql> select * from teachers;
+-----+---------------+-----+--------+
| TID | Name | Age | Gender |
+-----+---------------+-----+--------+
| 1 | Song Jiang | 45 | M |
| 2 | Zhang Sanfeng | 94 | M |
| 3 | Miejue Shitai | 77 | F |
| 4 | Lin Chaoying | 93 | F |
+-----+---------------+-----+--------+
-- 字符串直接拼接在一起不美观
mysql> select tid, concat(name, gender) from teachers;
+-----+----------------------+
| tid | concat(name, gender) |
+-----+----------------------+
| 1 | Song JiangM |
| 2 | Zhang SanfengM |
| 3 | Miejue ShitaiF |
| 4 | Lin ChaoyingF |
+-----+----------------------+
-- 使用空格作为分隔符
mysql> select tid, concat(name, ' ', gender) from teachers;
+-----+---------------------------+
| tid | concat(name, ' ', gender) |
+-----+---------------------------+
| 1 | Song Jiang M |
| 2 | Zhang Sanfeng M |
| 3 | Miejue Shitai F |
| 4 | Lin Chaoying F |
+-----+---------------------------+
-- 自定义列名
mysql> select tid, concat(name, ' ', gender) as 'name and gender' from teachers;
+-----+-----------------+
| tid | name and gender |
+-----+-----------------+
| 1 | Song Jiang M |
| 2 | Zhang Sanfeng M |
| 3 | Miejue Shitai F |
| 4 | Lin Chaoying F |
+-----+-----------------+其他
SUBSTRING(str, start, length) # 从字符串中提取子字符串。
UPPER(str) # 将字符串转换为大写。
LOWER(str) # 将字符串转换为小写。
LENGTH(str) # 返回字符串的长度。
TRIM([BOTH | LEADING | TRAILING] trim_character FROM str) # 去除字符串两侧或指定位置的空格或特定字符。DISTINCT
排除重复的行,仅返回每个不同的值。
SELECT DISTINCT column1, column2, ...
FROM table_name
WHERE condition;column1, column2, ...是要选择的列的名称。table_name是包含要检索数据的表的名称。condition是可选的条件,用于筛选满足特定条件的行。
注意事项:
- 使用
SELECT DISTINCT会增加查询的计算成本,因为数据库系统需要对结果进行额外的处理。在某些情况下,可以通过其他方式优化查询,例如使用GROUP BY和聚合函数。 SELECT DISTINCT关键字应用于所有指定的列。如果在SELECT语句中选择了多列,那么整个行的唯一性将由这些列的组合决定。
例子1:
mysql> select * from teachers;
+-----+---------------+-----+--------+
| TID | Name | Age | Gender |
+-----+---------------+-----+--------+
| 1 | Song Jiang | 45 | M |
| 2 | Zhang Sanfeng | 94 | M |
| 3 | Miejue Shitai | 77 | F |
| 4 | Lin Chaoying | 93 | F |
+-----+---------------+-----+--------+
mysql> select distinct gender from teachers;
+--------+
| gender |
+--------+
| M |
| F |
+--------+例子2:
mysql> select * from teachers;
+-----+---------------+-----+--------+
| TID | Name | Age | Gender |
+-----+---------------+-----+--------+
| 1 | Song Jiang | 45 | M |
| 2 | Zhang Sanfeng | 94 | M |
| 3 | Miejue Shitai | 77 | F |
| 4 | Lin Chaoying | 93 | F |
+-----+---------------+-----+--------+
-- 指定多列时,会将多列视为一个整体来去重(类似联合主键)。
mysql> select distinct gender, age from teachers;
+--------+-----+
| gender | age |
+--------+-----+
| M | 45 |
| M | 94 |
| F | 77 |
| F | 93 |
+--------+-----+SELECT 子句
AS
AS 子句在 SQL 中用于为列或表达式指定别名。别名是一个临时的名称,用于提高查询结果的可读性或简化查询中的语法。AS 子句是可选的,有时可以省略。
为列指定别名
SELECT column_name AS alias_name
FROM table_name;例子:
SELECT first_name AS employee_first_name, last_name AS employee_last_name
FROM employees;在这个例子中,AS 子句为 first_name 和 last_name 列指定了别名,分别为 employee_first_name 和 employee_last_name。
为表指定别名
SELECT column1, column2, ...
FROM table_name AS alias_name;例子:
SELECT e.first_name, e.last_name, d.department_name
FROM employees AS e
JOIN departments AS d ON e.department_id = d.department_id;在这个例子中,AS 子句为 employees 表和 departments 表分别指定了别名 e 和 d,使得在查询中可以使用更简洁的表名。
为表达式指定别名
SELECT column_name1 + column_name2 AS expression_alias
FROM table_name;例子:
SELECT salary * 12 AS annual_salary
FROM employees;在这个例子中,AS 子句为 salary * 12 表达式指定了别名 annual_salary,用于表示员工的年薪。
AS 子句在查询中经常用于为结果列和表指定更具描述性的名称,提高查询结果的可读性。需要注意的是,在大多数数据库管理系统中,AS 关键字是可选的,可以省略不写。例如,上面的例子也可以写成:
SELECT first_name employee_first_name, last_name employee_last_name
FROM employees;MariaDB [hellodb]> select tid 老师ID,name 姓名,age 年龄,gender 性别 from teachers;
+----------+---------------+--------+--------+
| 老师ID | 姓名 | 年龄 | 性别 |
+----------+---------------+--------+--------+
| 1 | Song Jiang | 45 | M |
| 2 | Zhang Sanfeng | 94 | M |
| 3 | Miejue Shitai | 77 | F |
| 4 | Lin Chaoying | 93 | F |
+----------+---------------+--------+--------+总之,AS 子句是 SQL 查询中用于为列、表或表达式指定别名的关键字,提高查询结果的可读性。
FROM
指定要查询的表或视图的来源。
FROM 子句是 SQL 查询中用于指定要从中检索数据的表或视图的子句。它通常是 SELECT 语句中的第一个子句,用于定义数据的来源。
基本的 FROM 子句形式如下:
SELECT column1, column2, ...
FROM table_name;其中:
column1, column2, ...是要选择的列的名称。table_name是包含要检索数据的表或视图的名称。
FROM 子句还可以包含多个表的列表,以支持联结操作。常见的多表 FROM 子句形式如下:
SELECT column1, column2, ...
FROM table1
JOIN table2 ON condition;其中:
table1和table2是要联结的表的名称。JOIN关键字用于指示联结操作。ON condition用于指定联结条件,即两个表之间的关联条件。
例子:
SELECT employees.first_name, employees.last_name, departments.department_name
FROM employees
JOIN departments ON employees.department_id = departments.department_id;在这个例子中,FROM 子句指定了 employees 表和 departments 表,使用 JOIN 和 ON 子句定义了这两个表之间的联结条件。
除了基本的 FROM 子句外,还有其他一些高级用法,例如使用子查询或使用视图。FROM 子句的灵活性使得可以从多个来源中检索数据,支持各种复杂的查询需求。
WHERE
筛选满足指定条件的行。
SELECT column1, column2, ...
FROM table_name
WHERE condition;column1, column2, ...是要选择的列的名称。table_name是包含要检索数据的表的名称。condition是用于筛选满足特定条件的行的表达式。
WHERE 子句中可以使用各种条件操作符,例如:
-
比较操作符(
=,<>,<,<=,>,>=,<=>) -
逻辑操作符(
AND,OR,NOT) -
模糊查询操作符(
LIKE,IN,BETWEEN,IS NULL)
比较操作符
=
MariaDB [hellodb]> select * from teachers;
+-----+---------------+-----+--------+
| TID | Name | Age | Gender |
+-----+---------------+-----+--------+
| 1 | Song Jiang | 45 | M |
| 2 | Zhang Sanfeng | 94 | M |
| 3 | Miejue Shitai | 77 | F |
| 4 | Lin Chaoying | 93 | F |
+-----+---------------+-----+--------+
## 筛选出 teachers 表中性别为 F 的所有内容
MariaDB [hellodb]> select * from teachers where gender='F';
+-----+---------------+-----+--------+
| TID | Name | Age | Gender |
+-----+---------------+-----+--------+
| 3 | Miejue Shitai | 77 | F |
| 4 | Lin Chaoying | 93 | F |
+-----+---------------+-----+--------+>=
MariaDB [hellodb]> select * from teachers;
+-----+---------------+-----+--------+
| TID | Name | Age | Gender |
+-----+---------------+-----+--------+
| 1 | Song Jiang | 45 | M |
| 2 | Zhang Sanfeng | 94 | M |
| 3 | Miejue Shitai | 77 | F |
| 4 | Lin Chaoying | 93 | F |
+-----+---------------+-----+--------+
## 筛选出 teachers 表中年龄大于等于 80 的所有内容
MariaDB [hellodb]> select * from teachers where age>=80;
+-----+---------------+-----+--------+
| TID | Name | Age | Gender |
+-----+---------------+-----+--------+
| 2 | Zhang Sanfeng | 94 | M |
| 4 | Lin Chaoying | 93 | F |
+-----+---------------+-----+--------+<>
- 不等于
MariaDB [hellodb]> select * from teachers;
+-----+---------------+-----+--------+
| TID | Name | Age | Gender |
+-----+---------------+-----+--------+
| 1 | Song Jiang | 45 | M |
| 2 | Zhang Sanfeng | 94 | M |
| 3 | Miejue Shitai | 77 | F |
| 4 | Lin Chaoying | 93 | F |
+-----+---------------+-----+--------+
## 筛选出 teachers 表中性别不为 M 的所有内容
MariaDB [hellodb]> select * from teachers where gender<>'M';
+-----+---------------+-----+--------+
| TID | Name | Age | Gender |
+-----+---------------+-----+--------+
| 3 | Miejue Shitai | 77 | F |
| 4 | Lin Chaoying | 93 | F |
+-----+---------------+-----+--------+mysql> select tid from teachers;
+-----+
| tid |
+-----+
| 1 |
| 2 |
| 3 |
| 4 |
+-----+
mysql> select tid from teachers where tid<>1 and tid<>3;
+-----+
| tid |
+-----+
| 2 |
| 4 |
+-----+
-- 等价于:
mysql> select tid from teachers where not (tid=1 or tid=3);
+-----+
| tid |
+-----+
| 2 |
| 4 |
+-----+
-- 推荐使用:
mysql> select tid from teachers where tid not in (1, 3);
+-----+
| tid |
+-----+
| 2 |
| 4 |
+-----+<=>
- 相等或都为空
逻辑操作符
AND
所有条件都为真时,整个条件表达式才为真。
SELECT column1, column2, ...
FROM table_name
WHERE condition1 AND condition2 AND ...;column1, column2, ...是要选择的列的名称。table_name是要查询的表的名称。condition1, condition2, ...是一个或多个布尔表达式,它们将被组合在一起,要求所有条件都为真。
需要注意的是,AND 关键字在条件表达式中的优先级高于 OR,但可以使用括号来明确条件的组合顺序。
例子:
-- 选择部门ID为1且薪水大于50000的员工
SELECT first_name, last_name, department_id, salary
FROM employees
WHERE department_id = 1 AND salary > 50000;
-- 选择注册日期在2022年且订单总额大于1000的订单
SELECT order_id, customer_id, order_date, total_amount
FROM orders
WHERE EXTRACT(YEAR FROM order_date) = 2022 AND total_amount > 1000;OR
至少有一个条件为真时,整个条件表达式就为真。
SELECT column1, column2, ...
FROM table_name
WHERE condition1 OR condition2 OR ...;column1, column2, ...是要选择的列的名称。table_name是要查询的表的名称。condition1, condition2, ...是一个或多个布尔表达式,它们将被组合在一起,要求至少有一个条件为真。
需要注意的是,AND 和 OR 关键字在条件表达式中的优先级,但可以使用括号来明确条件的组合顺序。
例子:
-- 选择部门ID为1或薪水大于50000的员工
SELECT first_name, last_name, department_id, salary
FROM employees
WHERE department_id = 1 OR salary > 50000;
-- 选择注册日期在2022年或订单总额大于1000的订单
SELECT order_id, customer_id, order_date, total_amount
FROM orders
WHERE EXTRACT(YEAR FROM order_date) = 2022 OR total_amount > 1000;NOT
它可以用于任何布尔表达式,将其结果取反。
SELECT column1, column2, ...
FROM table_name
WHERE NOT condition;column1, column2, ...是要选择的列的名称。table_name是要查询的表的名称。condition是一个布尔表达式,它可以是任何返回真或假的条件。
需要注意的是,NOT 关键字可以与其他逻辑操作符(如 AND、OR)一起使用,以构建更复杂的条件表达式。
例子1:
-- 选择不属于部门 1 的员工
SELECT first_name, last_name, department_id
FROM employees
WHERE NOT department_id = 1;
-- 选择注册日期不在 2022 年的订单
SELECT order_id, customer_id, order_date
FROM orders
WHERE NOT EXTRACT(YEAR FROM order_date) = 2022;例子2:
mysql> select tid from teachers;
+-----+
| tid |
+-----+
| 1 |
| 2 |
| 3 |
| 4 |
+-----+
mysql> select tid from teachers where not (tid=1 or tid=3);
+-----+
| tid |
+-----+
| 2 |
| 4 |
+-----+
-- 等价于:
mysql> select tid from teachers where tid<>1 and tid<>3;
+-----+
| tid |
+-----+
| 2 |
| 4 |
+-----+
-- 推荐使用:
mysql> select tid from teachers where tid not in (1, 3);
+-----+
| tid |
+-----+
| 2 |
| 4 |
+-----+模糊查询操作符
LIKE
模糊搜索(默认忽略大小写)
SELECT column1, column2, ...
FROM table_name
WHERE column_name LIKE pattern;column_name是要在其中进行模糊搜索的列的名称。pattern是模糊搜索的模式,通常包含通配符,常用的通配符有两个:%:任意长度的任意字符。表示零个或多个字符的占位符,可以匹配任意字符或字符序列。_:任意单个字符。表示一个字符的占位符,可以匹配任意单个字符。
注意事项:
- 如果要用
LIKE,尽量使用左前缀匹配,例如:p%,以提高查询性能。
例子1:
mysql> select name, age from students where age between 18 and 20 and name like 'x%';
+-------------+-----+
| name | age |
+-------------+-----+
| Xi Ren | 19 |
| Xue Baochai | 18 |
| Xiao Qiao | 20 |
+-------------+-----+例子2:
-- 匹配以 "John" 开头的任意名字
SELECT first_name, last_name
FROM employees
WHERE first_name LIKE 'John%';IN
挑选特定的字段
SELECT column1, column2, ...
FROM table_name
WHERE column_name IN (value1, value2, ...);column_name是要在其中进行条件筛选的列的名称。(value1, value2, ...)是一个包含要包含的值的值列表。
需要注意的是,如果值列表中存在 NULL,在某些数据库系统中 IN 的行为可能会受到影响,因为 NULL 与任何值的比较结果都是未知(UNKNOWN)。在这种情况下,可以考虑使用 EXISTS 或其他方式来处理。
范例1:
-- 所需字段不多时,可以用 OR。
SELECT * FROM students WHERE stuid=1 OR stuid=2 OR stuid=3;
-- 所需字段很多时,用 IN 更加方便。
SELECT * FROM students WHERE stuid IN (1, 2, 3);范例2:
-- 选择属于部门 1 或 2 的员工
SELECT first_name, last_name, department_id
FROM employees
WHERE department_id IN (1, 2);
-- 选择在指定城市的客户
SELECT customer_id, customer_name, city
FROM customers
WHERE city IN ('New York', 'Los Angeles', 'Chicago');NOT IN
排除特定的字段
SELECT column1, column2, ...
FROM table_name
WHERE column_name NOT IN (value1, value2, ...);column_name是要在其中进行条件筛选的列的名称。(value1, value2, ...)是一个包含要排除的值的值列表。
需要注意的是,如果值列表中存在 NULL,在某些数据库系统中 NOT IN 的行为可能会受到影响,因为 NULL 与任何值的比较结果都是未知(UNKNOWN)。在这种情况下,可以考虑使用 NOT EXISTS 或其他方式来处理。
例子:
-- 选择不属于部门 1 或 2 的员工
SELECT first_name, last_name, department_id
FROM employees
WHERE department_id NOT IN (1, 2);
-- 选择没有在指定城市的客户
SELECT customer_id, customer_name, city
FROM customers
WHERE city NOT IN ('New York', 'Los Angeles', 'Chicago');BETWEEN
范围之间
SELECT column1, column2, ...
FROM table_name
WHERE column_name BETWEEN value1 AND value2;column_name是要在其中进行范围筛选的列的名称。value1和value2是范围的两个边界值。- 在某些数据库系统中,也可以使用
BETWEEN ... AND ... - 1的方式来不包括右边界值。
- 在某些数据库系统中,也可以使用
例子1:
## 18到20岁之间
select age from students where age between 18 and 20;
## 等价于:
select age from students where age>=18 and age<=20;例子2:
-- 选择年龄在 25 到 35 之间的员工
SELECT first_name, last_name, age
FROM employees
WHERE age BETWEEN 25 AND 35;
-- 选择注册日期在 2022-01-01 到 2022-12-31 之间的订单
SELECT order_id, customer_id, order_date
FROM orders
WHERE order_date BETWEEN '2022-01-01' AND '2022-12-31';IS NULL
在 WHERE 子句中筛选出列值为 NULL 的行。
SELECT column1, column2, ...
FROM table_name
WHERE column_name IS NULL;column1, column2, ...是要选择的列的名称。table_name是要查询的表的名称。column_name是要在其中进行条件筛选的列的名称。
需要注意的是,与其他比较运算符不同,NULL 不能通过常规的比较运算符(如 = 或 <>)来检查,而必须使用 IS NULL 或 IS NOT NULL。
例子:
-- 选择没有分配部门的员工
SELECT first_name, last_name, department_id
FROM employees
WHERE department_id IS NULL;
-- 选择没有填写邮箱的客户
SELECT customer_id, customer_name, email
FROM customers
WHERE email IS NULL;IS NOT NULL
在 WHERE 子句中筛选出列值不为 NULL 的行。
SELECT column1, column2, ...
FROM table_name
WHERE column_name IS NOT NULL;column1, column2, ...是要选择的列的名称。table_name是要查询的表的名称。column_name是要在其中进行条件筛选的列的名称。
需要注意的是,与其他比较运算符不同,NULL 不能通过常规的比较运算符(如 = 或 <>)来检查,而必须使用 IS NULL 或 IS NOT NULL。
例子:
-- 选择分配了部门的员工
SELECT first_name, last_name, department_id
FROM employees
WHERE department_id IS NOT NULL;
-- 选择填写了邮箱的客户
SELECT customer_id, customer_name, email
FROM customers
WHERE email IS NOT NULL;在这些例子中,IS NOT NULL 子句用于筛选列值不为 NULL 的行。
范例:多种操作符组合
例子:
SELECT product_name, price
FROM products
WHERE category = 'Electronics' AND price > 500
ORDER BY price DESC;在这个例子中,WHERE 子句筛选了类别为 ‘Electronics’ 且价格大于 500 的产品,并使用 ORDER BY 子句对结果进行降序排序。
例子:
SELECT first_name, last_name, salary
FROM employees
WHERE department = 'IT' AND salary > 50000;在这个例子中,WHERE 子句指定了两个条件:部门为 ‘IT’ 且工资大于 50000。只有满足这两个条件的员工的信息才会被检索。
GROUP BY
将结果集按一个或多个列分组。GROUP BY 子句通常与聚合函数一起使用,以对每个组进行聚合计算。
SELECT column1, column2, ..., aggregate_function(column)
FROM table_name
WHERE condition
GROUP BY column1, column2, ...;column1, column2, ...是要选择的列的名称,也是用于分组的列。aggregate_function(column)是应用于每个组的聚合函数,例如SUM,AVG,COUNT,MIN,MAX等。condition是可选的条件,用于筛选满足特定条件的行。
例子1:
SELECT department, AVG(salary) AS avg_salary
FROM employees
GROUP BY department;在这个例子中,GROUP BY 子句按部门对员工进行分组,并计算每个部门的平均工资。
例子2:
GROUP BY 子句可以包含多个列,以创建更细粒度的分组。例如:
SELECT department, job_title, AVG(salary) AS avg_salary
FROM employees
GROUP BY department, job_title;在这个例子中,GROUP BY 子句按部门和职位对员工进行分组,并计算每个部门和职位的平均工资。
范例3:
## 将男女分组,取平均年龄,和最大,最小年龄
MariaDB [hellodb]> SELECT gender,avg(age),max(age),min(age) FROM students GROUP BY gender;
+--------+----------+----------+----------+
| gender | avg(age) | max(age) | min(age) |
+--------+----------+----------+----------+
| F | 19.0000 | 22 | 17 |
| M | 33.0000 | 100 | 19 |
+--------+----------+----------+----------+
## 起别名更直观
MariaDB [hellodb]> SELECT gender,avg(age) 平均年龄,max(age) 最大年龄,min(age) 最小年龄 FROM students GROUP BY gender;
+--------+--------------+--------------+--------------+
| gender | 平均年龄 | 最大年龄 | 最小年龄 |
+--------+--------------+--------------+--------------+
| F | 19.0000 | 22 | 17 |
| M | 33.0000 | 100 | 19 |
+--------+--------------+--------------+--------------+
## 取每个班的男生和女生平均年龄
MariaDB [hellodb]> SELECT classid,gender,avg(age) FROM students GROUP BY classid,gender;
+---------+--------+----------+
| classid | gender | avg(age) |
+---------+--------+----------+
| NULL | M | 63.5000 |
| 1 | F | 19.5000 |
| 1 | M | 21.5000 |
| 2 | M | 36.0000 |
| 3 | F | 18.3333 |
| 3 | M | 26.0000 |
| 4 | M | 24.7500 |
| 5 | M | 46.0000 |
| 6 | F | 20.0000 |
| 6 | M | 23.0000 |
| 7 | F | 18.0000 |
| 7 | M | 23.0000 |
+---------+--------+----------+
-- 通过 WHERE 过滤掉 classid 为 NULL 的列
mysql> SELECT classid,gender,avg(age) FROM students WHERE classid IS NOT NULL GROUP BY classid,gender;
+---------+--------+----------+
| classid | gender | avg(age) |
+---------+--------+----------+
| 2 | M | 36.0000 |
| 1 | M | 21.5000 |
| 4 | M | 24.7500 |
| 3 | M | 26.0000 |
| 5 | M | 46.0000 |
| 3 | F | 18.3333 |
| 7 | F | 18.0000 |
| 6 | F | 20.0000 |
| 6 | M | 23.0000 |
| 1 | F | 19.5000 |
| 7 | M | 23.0000 |
+---------+--------+----------+注意事项:
进行分组后,SELECT 子句后面要么加分组的字段本身,要么加聚合函数,否则没有意义。
SELECT department, job_title, AVG(salary) AS avg_salary
FROM employees
GROUP BY department, job_title;在这个例子中,department 和 job_title 出现在 GROUP BY 子句和 SELECT 子句中,而 AVG(salary) 是一个聚合函数,也出现在 SELECT 子句中。
HAVING
HAVING 子句通常与 GROUP BY 子句一起使用,用于在分组后对分组结果进行条件筛选。
HAVING 子句允许你过滤掉不满足特定条件的分组,而 WHERE 子句用于在分组前对行进行筛选。
WHERE 中的操作符,在 HAVING 中同样可用
SELECT column1, column2, ..., aggregate_function(column)
FROM table_name
WHERE condition
GROUP BY column1, column2, ...
HAVING condition;column1, column2, ...是要选择的列的名称,也是用于分组的列。aggregate_function(column)是应用于每个组的聚合函数,例如SUM,AVG,COUNT,MIN,MAX等。table_name是包含要检索数据的表的名称。condition是用于筛选分组结果的条件。
注意事项:
HAVING子句仅在使用了GROUP BY子句时才有效。如果没有使用GROUP BY,则HAVING将被当作WHERE子句处理。
例子1:
SELECT department, AVG(salary) AS avg_salary
FROM employees
GROUP BY department
HAVING AVG(salary) > 50000;在这个例子中,HAVING 子句用于筛选出平均工资大于 50000 的部门。
例子2:
与 WHERE 子句不同的是,HAVING 子句使用聚合函数的结果进行条件判断。因此,你可以在 HAVING 子句中使用诸如 SUM, AVG, COUNT, MIN, MAX 等聚合函数。
SELECT department, COUNT(*) AS employee_count
FROM employees
GROUP BY department
-- HAVING COUNT(*) > 5;
HAVING employee_count > 5;在这个例子中,HAVING 子句用于筛选出员工数量大于 5 的部门。
例子3:
## 取每个班的平均年龄
MariaDB [hellodb]> SELECT classid,avg(age) FROM students GROUP BY classid;
+---------+----------+
| classid | avg(age) |
+---------+----------+
| NULL | 63.5000 |
| 1 | 20.5000 |
| 2 | 36.0000 |
| 3 | 20.2500 |
| 4 | 24.7500 |
| 5 | 46.0000 |
| 6 | 20.7500 |
| 7 | 19.6667 |
+---------+----------+
## 取每个班的平均年龄,过滤classid为NULL的班级
MariaDB [hellodb]> SELECT classid,avg(age) FROM students GROUP BY classid WHERE classid IS NOT NULL;
ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MariaDB server version for the right syntax to use near 'WHERE classid IS NOT NULL' at line 1 # 分组后用WHERE会报错
## 正确方法分组后使用 HAVING
MariaDB [hellodb]> SELECT classid,avg(age) FROM students GROUP BY classid HAVING classid IS NOT NULL;
+---------+----------+
| classid | avg(age) |
+---------+----------+
| 1 | 20.5000 |
| 2 | 36.0000 |
| 3 | 20.2500 |
| 4 | 24.7500 |
| 5 | 46.0000 |
| 6 | 20.7500 |
| 7 | 19.6667 |
+---------+----------+
## 或 WHERE 在前(推荐用法)
MariaDB [hellodb]> SELECT classid,avg(age) FROM students WHERE classid IS NOT NULL GROUP BY classid;
+---------+----------+
| classid | avg(age) |
+---------+----------+
| 1 | 20.5000 |
| 2 | 36.0000 |
| 3 | 20.2500 |
| 4 | 24.7500 |
| 5 | 46.0000 |
| 6 | 20.7500 |
| 7 | 19.6667 |
+---------+----------+ORDER BY
对结果集进行排序。
SELECT column1, column2, ...
FROM table_name
WHERE condition
ORDER BY column1 [ASC | DESC], column2 [ASC | DESC], ...;condition是可选的条件,用于筛选满足特定条件的行。column1 [ASC | DESC], column2 [ASC | DESC], ...是要排序的列的列表,ASC表示升序(默认),DESC表示降序。
例子1:
SELECT first_name, last_name, salary
FROM employees
WHERE department = 'IT'
ORDER BY salary DESC;在这个例子中,ORDER BY 子句按照工资列的降序对 IT 部门的员工进行排序。
例子2:
ORDER BY 子句还可以使用列的位置号进行排序,而不是列名。例如:
SELECT first_name, last_name, salary
FROM employees
WHERE department = 'Sales'
ORDER BY 3 DESC, 1 ASC;在这个例子中,ORDER BY 子句按照第 3 列(salary 列)的降序和第 1 列(first_name 列)的升序对销售部门的员工进行排序。
例子3:
可以在 ORDER BY 子句中同时指定多个列,以便进行多级排序。例如:
SELECT department, job_title, AVG(salary) AS avg_salary
FROM employees
GROUP BY department, job_title
ORDER BY department ASC, avg_salary DESC;在这个例子中,ORDER BY 子句首先按照部门升序排序,然后在每个部门内按照平均工资降序排序。
注意:如果排序的列中存在NULL,则NULL会排列在前,下面的命令’’-classid desc;“可以将NULL排在最后
SELECT *
FROM students
ORDER BY -classid desc;LIMIT
限制结果集的行数。
语法一
LIMIT row_countrow_count指定要返回的行数。
例子:
## 只显示前三个
MariaDB [hellodb]> SELECT * FROM students ORDER BY stuid LIMIT 3;
+-------+-------------+-----+--------+---------+-----------+
| StuID | Name | Age | Gender | ClassID | TeacherID |
+-------+-------------+-----+--------+---------+-----------+
| 1 | Shi Zhongyu | 22 | M | 2 | 3 |
| 2 | Shi Potian | 22 | M | 1 | 7 |
| 3 | Xie Yanke | 53 | M | 2 | 16 |
+-------+-------------+-----+--------+---------+-----------+语法二
LIMIT + OFFSET 的简写方式
LIMIT offset, row_count
## 也可以理解为:
LIMIT start, len例子:
## 跳过前两个,显示两个后面的三个
MariaDB [hellodb]> SELECT * FROM students ORDER BY stuid LIMIT 2,3;
+-------+-----------+-----+--------+---------+-----------+
| StuID | Name | Age | Gender | ClassID | TeacherID |
+-------+-----------+-----+--------+---------+-----------+
| 3 | Xie Yanke | 53 | M | 2 | 16 |
| 4 | Ding Dian | 32 | M | 4 | 4 |
| 5 | Yu Yutong | 26 | M | 3 | 1 |
+-------+-----------+-----+--------+---------+-----------+
## 等价于:
SELECT * FROM students ORDER BY stuid LIMIT 3 OFFSET 2;注意:过滤的数值如果有并列相同的情况,可能会丢失一些内容
这句话的意思是,当使用 LIMIT 子句对查询结果进行限制时,如果查询结果中存在多个具有相同排序值的行,那么在取结果时可能会丢失一些内容。具体来说,如果在排序列上有多个行具有相同的值,并且这些行恰好位于限制范围的边界上,那么只有部分相同值的行会被返回,而另一部分则可能会被丢弃。
例如,在上述示例中,使用 LIMIT 2,3 对学生表进行查询,并按 StuID 列进行排序。如果在 StuID 列上有多个学生具有相同的 StuID 值,那么只有其中的一部分学生会被返回,而另一部分可能会被丢弃,导致结果集中可能会缺少某些学生的信息。
这种情况通常在使用 LIMIT 子句时需要注意,特别是当对具有相同排序值的列进行分页查询时。如果确保不丢失任何数据是必要的,可能需要通过其他方式来处理,如使用主键或唯一键进行排序。
OFFSET
OFFSET 子句是 SQL 查询中用于指定结果集中要跳过的行数的子句。通常与 LIMIT 子句一起使用,用于实现分页功能。
语法:
LIMIT row_count OFFSET offset;row_count指定要返回的行数。offset指定要跳过的行数。
例子:
SELECT first_name, last_name
FROM employees
ORDER BY last_name
LIMIT 10 OFFSET 20;在这个例子中,返回按姓氏升序排序的员工名字,从结果集的第 21 行开始,返回接下来的 10 行。这样的查询结果可以用于实现分页,获取每页的数据。
SELECT 多表查询
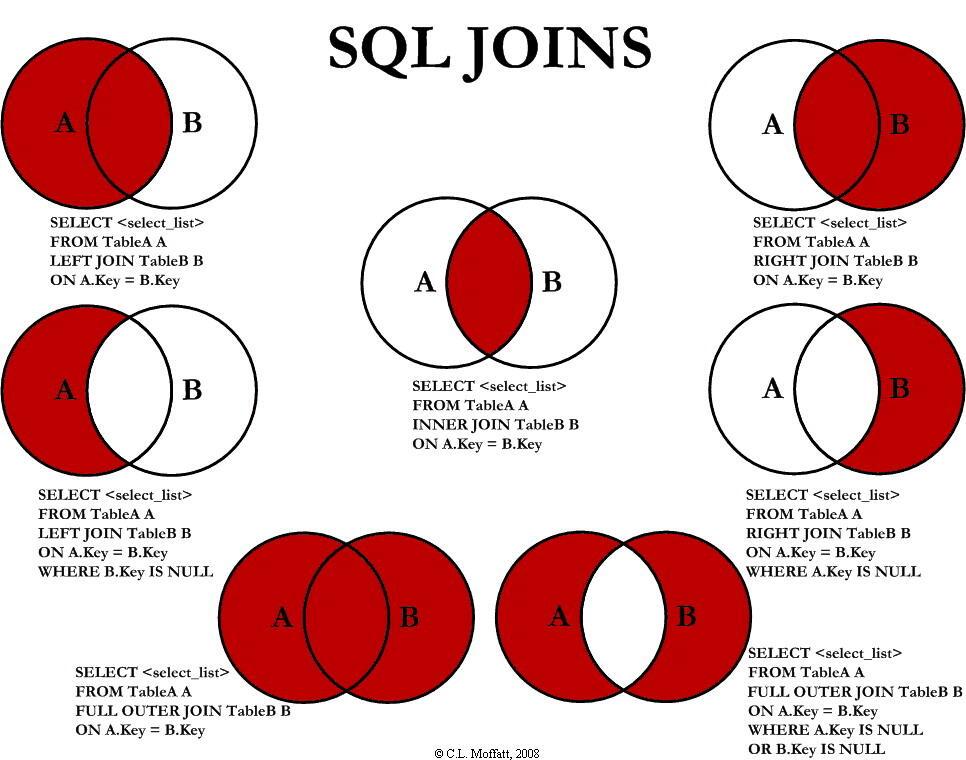
JOIN 子句可以有不同的类型,包括:
INNER JOIN:返回匹配的行,即两个表中都存在的行。LEFT JOIN(或LEFT OUTER JOIN):返回左表中的所有行,以及右表中匹配的行。RIGHT JOIN(或RIGHT OUTER JOIN):返回右表中的所有行,以及左表中匹配的行。FULL JOIN(或FULL OUTER JOIN):返回左表和右表中的所有行,以及两者之间匹配的行。CROSS JOIN:返回两个表的笛卡尔积,即左表的每一行与右表的每一行的组合。
例子:
SELECT employees.first_name, employees.last_name, departments.department_name
FROM employees
LEFT JOIN departments ON employees.department_id = departments.department_id;在这个例子中,使用 LEFT JOIN 返回了所有员工的名字以及对应部门的名称,即使员工的部门在 departments 表中没有匹配的记录。
() 子查询
子查询(Subquery),也称为嵌套查询或内部查询,是指在一个 SQL 查询语句中嵌套另一个完整的 SELECT 查询语句。子查询可以出现在 SELECT、FROM、WHERE、HAVING 或 INSERT INTO 语句中的任何位置。
子查询的作用是在主查询的基础上执行额外的查询,以便根据子查询的结果来进一步过滤、计算或检索数据。子查询通常返回一个结果集,该结果集可以是一个值、一列值或多行值,取决于子查询的具体形式和位置。
注意事项:
- 子查询性能较差;
- 子查询必须在一组小括号内;
- 子查询中不能使用
ORDER BY
以下是几种常见的子查询示例:
在 WHERE 子句中使用子查询
结合比较表达式
-- 查询students表中年龄大于teachers表平均年龄的人
SELECT Name,Age FROM students WHERE Age>(SELECT avg(Age) FROM teachers);子查询返回结果需为一个值,否则将报错。
结合 IN
-- 查询students表中学生年龄 和 teachers表中老师年龄相同的学生
SELECT Name,Age FROM students WHERE Age IN (SELECT Age FROM teachers);子查询返回结果需为一个或多个值组成的列表,否则将报错。
SELECT * FROM orders WHERE customer_id IN (SELECT customer_id FROM customers WHERE country = 'USA');在这个例子中,子查询 SELECT customer_id FROM customers WHERE country = 'USA' 返回所有国家为美国的客户的 customer_id,然后主查询根据这些客户的 customer_id 在 orders 表中检索相应的订单信息。
结合 EXISTS 与 NOT EXISTS
- EXISTS (或 NOT EXISTS) 用在 where之后,且后面紧跟子查询语句(带括号)
- EXISTS (或 NOT EXISTS) 只关心子查询有没有结果,并不关心子查询的结果具体是什么
- 下述语句把students的记录逐条代入到Exists后面的子查询中,如果子查询结果集不为空,即说明存在,那么这条students的记录出现在最终结果集,否则被排除
-- 查询学生表中Teacherid 和 Teachers表中的tid对等的内容
mysql> select * from students s where EXISTS (select * from teachers t where s.teacherid=t.tid);
+-------+-------------+-----+--------+---------+-----------+
| StuID | Name | Age | Gender | ClassID | TeacherID |
+-------+-------------+-----+--------+---------+-----------+
| 1 | Shi Zhongyu | 22 | M | 2 | 3 |
| 4 | Ding Dian | 32 | M | 4 | 4 |
| 5 | Yu Yutong | 26 | M | 3 | 1 |
+-------+-------------+-----+--------+---------+-----------+
-- 查询学生表中Teacherid 和 Teachers表中的tid不对等的内容
mysql> select * from students s where NOT EXISTS (select * from teachers t where s.teacherid=t.tid);
+-------+---------------+-----+--------+---------+-----------+
| StuID | Name | Age | Gender | ClassID | TeacherID |
+-------+---------------+-----+--------+---------+-----------+
| 2 | Shi Potian | 22 | M | 1 | 7 |
| 3 | Xie Yanke | 53 | M | 2 | 16 |
| 6 | Shi Qing | 46 | M | 5 | NULL |
| 7 | Xi Ren | 19 | F | 3 | NULL |
| 8 | Lin Daiyu | 17 | F | 7 | NULL |
| 9 | Ren Yingying | 20 | F | 6 | NULL |
| 10 | Yue Lingshan | 19 | F | 3 | NULL |
| 11 | Yuan Chengzhi | 23 | M | 6 | NULL |
| 12 | Wen Qingqing | 19 | F | 1 | NULL |
| 13 | Tian Boguang | 33 | M | 2 | NULL |
| 14 | Lu Wushuang | 17 | F | 3 | NULL |
| 15 | Duan Yu | 19 | M | 4 | NULL |
| 16 | Xu Zhu | 21 | M | 1 | NULL |
| 17 | Lin Chong | 25 | M | 4 | NULL |
| 18 | Hua Rong | 23 | M | 7 | NULL |
| 19 | Xue Baochai | 18 | F | 6 | NULL |
| 20 | Diao Chan | 19 | F | 7 | NULL |
| 21 | Huang Yueying | 22 | F | 6 | NULL |
| 22 | Xiao Qiao | 20 | F | 1 | NULL |
| 23 | Ma Chao | 23 | M | 4 | NULL |
| 24 | Xu Xian | 27 | M | NULL | NULL |
| 25 | Sun Dasheng | 100 | M | NULL | NULL |
+-------+---------------+-----+--------+---------+-----------+
-- students表原有内容
mysql> select * from students;
+-------+---------------+-----+--------+---------+-----------+
| StuID | Name | Age | Gender | ClassID | TeacherID |
+-------+---------------+-----+--------+---------+-----------+
| 1 | Shi Zhongyu | 22 | M | 2 | 3 |
| 2 | Shi Potian | 22 | M | 1 | 7 |
| 3 | Xie Yanke | 53 | M | 2 | 16 |
| 4 | Ding Dian | 32 | M | 4 | 4 |
| 5 | Yu Yutong | 26 | M | 3 | 1 |
| 6 | Shi Qing | 46 | M | 5 | NULL |
| 7 | Xi Ren | 19 | F | 3 | NULL |
| 8 | Lin Daiyu | 17 | F | 7 | NULL |
| 9 | Ren Yingying | 20 | F | 6 | NULL |
| 10 | Yue Lingshan | 19 | F | 3 | NULL |
| 11 | Yuan Chengzhi | 23 | M | 6 | NULL |
| 12 | Wen Qingqing | 19 | F | 1 | NULL |
| 13 | Tian Boguang | 33 | M | 2 | NULL |
| 14 | Lu Wushuang | 17 | F | 3 | NULL |
| 15 | Duan Yu | 19 | M | 4 | NULL |
| 16 | Xu Zhu | 21 | M | 1 | NULL |
| 17 | Lin Chong | 25 | M | 4 | NULL |
| 18 | Hua Rong | 23 | M | 7 | NULL |
| 19 | Xue Baochai | 18 | F | 6 | NULL |
| 20 | Diao Chan | 19 | F | 7 | NULL |
| 21 | Huang Yueying | 22 | F | 6 | NULL |
| 22 | Xiao Qiao | 20 | F | 1 | NULL |
| 23 | Ma Chao | 23 | M | 4 | NULL |
| 24 | Xu Xian | 27 | M | NULL | NULL |
| 25 | Sun Dasheng | 100 | M | NULL | NULL |
+-------+---------------+-----+--------+---------+-----------+
-- teachers表原有内容
mysql> select * from teachers;
+-----+---------------+-----+--------+
| TID | Name | Age | Gender |
+-----+---------------+-----+--------+
| 1 | Song Jiang | 45 | M |
| 2 | Zhang Sanfeng | 94 | M |
| 3 | Miejue Shitai | 77 | F |
| 4 | Lin Chaoying | 93 | F |
+-----+---------------+-----+--------+
4 rows in set (0.00 sec)在 FROM 子句中使用子查询
子查询当表用
语法:
SELECT tb_alias.col1,... FROM (SELECT clause) AS tb_alias WHERE Clause;例子1:
SELECT * FROM (SELECT product_id, SUM(quantity) AS total_sold FROM order_details GROUP BY product_id) AS sales_summary WHERE total_sold > 100;这个例子中,子查询 SELECT product_id, SUM(quantity) AS total_sold FROM order_details GROUP BY product_id 返回每个产品的总销售量,然后外部查询将这些结果作为临时表 sales_summary,并从中选择总销售量超过 100 的产品。
例子2:
SELECT class_avg_age.ClassID, class_avg_age.avg_age FROM (SELECT avg(Age) AS avg_age, ClassID FROM students WHERE ClassID IS NOT NULL GROUP BY ClassID) AS class_avg_age WHERE class_avg_age.avg_age>30;
-- 子查询 (SELECT avg(Age) AS avg_age, ClassID FROM students WHERE ClassID IS NOT NULL GROUP BY ClassID) AS s,计算每个班级的平均年龄,并将其作为新表并命名为 class_avg_age
-- 最后只取 class_avg_age 表中平均年龄大于30的班级
SELECT name,age FROM (SELECT * FROM students WHERE age>=30) AS old_students;
-- 子查询 SELECT * FROM students WHERE age>=30,将 students 表中的学生年龄大于30岁的过滤出来,命名为 old_students
-- 然后从中挑选出name和age字段进行展示在 SELECT 子句中使用子查询
SELECT product_name, (SELECT AVG(price) FROM products WHERE category_id = categories.category_id) AS avg_price FROM products;在这个例子中,子查询 SELECT AVG(price) FROM products WHERE category_id = categories.category_id 计算了每个产品类别的平均价格,并将其作为 avg_price 列返回。
在 UPDATE 中使用子查询
- 子查询的结果用于更新数据
MariaDB [hellodb]> SELECT avg(age) FROM students; # 学生表平均年龄
+----------+
| avg(age) |
+----------+
| 27.4000 |
+----------+
MariaDB [hellodb]> SELECT * FROM teachers; # 老师表的年龄
+-----+---------------+-----+--------+
| TID | Name | Age | Gender |
+-----+---------------+-----+--------+
| 1 | Song Jiang | 45 | M |
| 2 | Zhang Sanfeng | 94 | M |
| 3 | Miejue Shitai | 77 | F |
| 4 | Lin Chaoying | 93 | F |
+-----+---------------+-----+--------+
## 将teachers表中tid为4的人的年龄改为students表的平均年龄
MariaDB [hellodb]> UPDATE teachers SET age=(SELECT avg(age) FROM students) WHERE tid=4;
MariaDB [hellodb]> SELECT * FROM teachers;
+-----+---------------+-----+--------+
| TID | Name | Age | Gender |
+-----+---------------+-----+--------+
| 1 | Song Jiang | 45 | M |
| 2 | Zhang Sanfeng | 94 | M |
| 3 | Miejue Shitai | 77 | F |
| 4 | Lin Chaoying | 27 | F |
+-----+---------------+-----+--------+JOIN
关联两个或多个表的数据,以便可以从这些表中检索相关联的信息。
SELECT column1, column2, ...
FROM table1
JOIN table2 ON table1.column_name = table2.column_name;
-- 也可以使用 WHERE,但建议用 ON,因为 ON 执行的更早
-- JOIN table2 WHERE table1.column_name = table2.column_name;column1, column2, ...是要选择的列的名称。table1和table2是要联结的表的名称。JOIN关键字用于指示联结操作。ON table1.column_name = table2.column_name是指定联结条件的部分,它定义了两个表之间的关联。
注意事项:
- JOIN 时如不加 ON 等过滤条件,将返回两张或多张表的笛卡尔乘积,因此查询时务必要加 ON 或 WHERE。
例子1:
select *
from teachers t
join students s on t.tid = s.teacherid;例子2:
SELECT employees.first_name, employees.last_name, departments.department_name
FROM employees
JOIN departments ON employees.department_id = departments.department_id;在这个例子中,JOIN 子句将 employees 表与 departments 表联结起来,通过 department_id 列进行关联。查询返回了员工的名字以及对应部门的名称。
INNER JOIN
返回匹配的行。
INNER JOIN 子句是 SQL 查询中用于返回两个表中匹配行的子句。它只返回两个表中关联列具有匹配值的行。
基本的 INNER JOIN 子句形式如下:
SELECT column1, column2, ...
FROM table1
INNER JOIN table2 ON table1.column_name = table2.column_name;其中:
column1, column2, ...是要选择的列的名称。table1和table2是要联结的表的名称。INNER JOIN关键字用于指示联结操作。ON table1.column_name = table2.column_name是指定联结条件的部分,它定义了两个表之间的关联。
例子:
SELECT employees.first_name, employees.last_name, departments.department_name
FROM employees
INNER JOIN departments ON employees.department_id = departments.department_id;在这个例子中,INNER JOIN 子句将 employees 表与 departments 表联结起来,通过 department_id 列进行关联。查询返回了员工的名字以及对应部门的名称,只包含那些在两个表中都存在的匹配行。
INNER JOIN 只返回匹配的行,如果两个表中的关联列没有匹配值,则这些行将不包含在结果中。这使得 INNER JOIN 适用于需要在两个表中查找匹配数据的情况。
总之,INNER JOIN 子句是 SQL 查询中用于返回两个表中匹配行的关键字,只返回满足联结条件的行。
CROSS JOIN
-
交叉连接,返回两个表的笛卡尔积(所有可能的组合)的子句。
-
# 笛卡儿积范例: # echo {a,b}.{log,txt,html} a.log a.txt a.html b.log b.txt b.html
-
-
CROSS JOIN将左表的每一行与右表的每一行进行组合,生成的结果集行数等于左表的行数乘以右表的行数。
-- 基本的 CROSS JOIN 子句形式如下:
SELECT column1, column2, ...
FROM table1
CROSS JOIN table2;column1, column2, ...是要选择的列的名称。table1和table2是要联结的表的名称。CROSS JOIN关键字用于指示联结操作。
注意事项:
- 交叉连接在表数量巨大时尽量不要查询,因为数据量太大,有可能导致数据库崩溃,使用场景较少。
例子1:
SELECT employees.first_name, employees.last_name, departments.department_name
FROM employees
CROSS JOIN departments;在这个例子中,CROSS JOIN 子句将 employees 表的每一行与 departments 表的每一行进行组合。结果集包含了所有可能的员工和部门的组合。
例子2:
- 将交叉连接后的内容进行过滤
-- 错误过滤
SELECT stuid,name,age,tid,name,age FROM students CROSS JOIN teachers;
ERROR 1052 (23000): Column 'name' in field list is ambiguous -- 内容模糊不清,因为两张表中都有name和age
-- 正确过滤方式1,标明是针对哪张表的name和age
SELECT stuid,students.name,students.age,tid,teachers.name,teachers.age FROM students CROSS JOIN teachers;
-- 正确过滤方式2,给表起别名,然后使用表的别名来表示是针对哪张表的name和age
SELECT stuid,s.name,s.age,tid,t.name,t.age FROM students s CROSS JOIN teachers t;
-- 正确过滤方式3,给表起别名,然后使用表的别名来表示是针对哪张表的name和age,最后在给显示效果起别名便于阅读
SELECT stuid,s.name 学生姓名,s.age 学生年龄,tid,t.name 老师姓名,t.age 老师年龄 FROM students s CROSS JOIN teachers t;A表和B表,A表在左 B表在右,A表显示全部内容,B表取和A表的交集,B表与A表无交集的地方显示为NULL
LEFT JOIN
左连接,左表返回所有行,右表返回与左表有交集的行,右表无交集的地方显示为NULL
SELECT column1, column2, ...
FROM table1
LEFT JOIN table2 ON table1.column_name = table2.column_name;column1, column2, ...是要选择的列的名称。table1和table2是要联结的表的名称。LEFT JOIN关键字(或LEFT OUTER JOIN)用于指示联结操作。ON table1.column_name = table2.column_name是指定联结条件的部分,它定义了两个表之间的关联。
应用场景:
- 通常用于需要显示主表(左表)中的所有数据,而附表(右表)中的匹配数据是可选的情况。
例子1:
select * from teachers t left join students s on t.tid = s.teacherid;
select * from classes c left join students s on c.ClassID = s.ClassID;例子2:
SELECT <select_list> FROM TableA A LEFT JOIN TableB B ON A.Key=B.Key WHERE B.Key IS NULL;
-- 左外连接扩展,只取A表中与B表非交集的内容
-- A表和B表,A表在左,B表在右,A表匹配除和B表交集外的内容
-- B.Key IS NULL只显示NULL就表示排除交集了
select * from students s left join teachers t on s.teacherid=t.tid where tid is null;
-- where t.tid is null,teacher表的tid是null的即代表排除交集,只显示非交集的内容
select * from students s left join teachers t on s.teacherid=t.tid where t.tid is not null;
-- 只取交集,相当于INNER JOIN了例子3:
SELECT employees.first_name, employees.last_name, departments.department_name
FROM employees
LEFT JOIN departments ON employees.department_id = departments.department_id;在这个例子中,LEFT JOIN 子句将 employees 表与 departments 表联结起来,通过 department_id 列进行关联。查询返回了员工的名字以及对应部门的名称,包括左表中的所有行,即使在右表中没有匹配的行,对应的部门名称将为 NULL。
RIGHT JOIN
右连接,右表返回所有行,左表返回与右表有交集的行,左表无交集的地方显示为NULL
SELECT column1, column2, ...
FROM table1
RIGHT JOIN table2 ON table1.column_name = table2.column_name;column1, column2, ...是要选择的列的名称。table1和table2是要联结的表的名称。RIGHT JOIN关键字(或RIGHT OUTER JOIN)用于指示联结操作。ON table1.column_name = table2.column_name是指定联结条件的部分,它定义了两个表之间的关联。
例子1:
select * from teachers t right join students s on t.tid = s.teacherid;例子2:
SELECT employees.first_name, employees.last_name, departments.department_name
FROM employees
RIGHT JOIN departments ON employees.department_id = departments.department_id;在这个例子中,RIGHT JOIN 子句将 employees 表与 departments 表联结起来,通过 department_id 列进行关联。查询返回了员工的名字以及对应部门的名称,包括右表中的所有行,即使在左表中没有匹配的行,对应的员工信息将为 NULL。
自连接
自连接(Self-Join)是指在同一个表中进行连接操作,即将表视为两个不同的实体来进行连接。
即表自身连接自身,假设本身只有一张表,利用这仅有的一张表模拟成两张表(通过起不同别名的方式)来进行查询
应用场景:
- 通常用于所需的结果都来自于一张表,而在一张表中使用一条SQL语句无法完成查询的时候需要用到自连接这种方式来进行查询。
- 自连接常用于需要将表中的某些数据与同一表中的其他数据进行比较或匹配的情况。
注意事项:
- 自连接可能会导致查询变得复杂和低效,特别是在连接的表非常大的情况下。因此,在使用自连接时,需要仔细考虑查询的性能和效率,并根据具体情况进行优化。
例子1:
-- 创建测试表
MariaDB [hellodb]> CREATE TABLE emp (id int auto_increment primary key,name varchar(20),leader_id int);
MariaDB [hellodb]> desc emp;
+-----------+-------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-----------+-------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| name | varchar(20) | YES | | NULL | |
| leader_id | int(11) | YES | | NULL | |
+-----------+-------------+------+-----+---------+----------------+
MariaDB [hellodb]> INSERT emp (name,leader_id)values('mage',null),('zhangsir',1),('wang',2),('zhang',3);
MariaDB [hellodb]> select * from emp;
+----+----------+-----------+
| id | name | leader_id |
+----+----------+-----------+
| 1 | mage | NULL |
| 2 | zhangsir | 1 |
| 3 | wang | 2 |
| 4 | zhang | 3 |
+----+----------+-----------+
-- 显示员工姓名和对应的领导姓名:
-- 不常用,利用内连接INNER JOIN然后起别名的方式实现,但是因为INNER JOIN只会取交集,而mage没有所对应的leader 所以无交集 因此mage不会显示
MariaDB [hellodb]> SELECT e.name 员工姓名,l.name 领导姓名 FROM emp e INNER JOIN emp l ON e.leader_id=l.id;
+--------------+--------------+
| 员工姓名 | 领导姓名 |
+--------------+--------------+
| zhangsir | mage |
| wang | zhangsir |
| zhang | wang |
+--------------+--------------+
## 常用,利用左外连接LEFT JOIN(RIGHT JOIN也可以)然后起别名的方式实现,因为LEFT JOIN会将左边的内容全部显示 所以mage也会出现
MariaDB [hellodb]> SELECT e.name 员工姓名,l.name 领导姓名 FROM emp e LEFT JOIN emp l ON e.leader_id=l.id;
+--------------+--------------+
| 员工姓名 | 领导姓名 |
+--------------+--------------+
| mage | NULL |
| zhangsir | mage |
| wang | zhangsir |
| zhang | wang |
+--------------+--------------+
## 还可以利用IFNULL这个函数替换NULL的值
MariaDB [hellodb]> SELECT e.name 员工姓名,IFNULL(l.name,'无上级') 领导姓名 FROM emp e LEFT JOIN emp l ON e.leader_id=l.id;
+--------------+--------------+
| 员工姓名 | 领导姓名 |
+--------------+--------------+
| mage | 无上级 |
| zhangsir | mage |
| wang | zhangsir |
| zhang | wang |
+--------------+--------------+例子2:
假设我们有一个表 employees 包含员工信息,每个员工有一个经理,经理也是员工,我们想要找到每个员工的经理姓名:
SELECT e.name AS employee_name, m.name AS manager_name
FROM employees e
JOIN employees m ON e.manager_id = m.employee_id;在这个查询中,我们使用了自连接。employees e 和 employees m 是同一个表的两个实例,通过 JOIN 操作将它们连接起来。然后我们指定了连接条件 e.manager_id = m.employee_id,表示每个员工的 manager_id 应该与另一个员工的 employee_id 匹配,从而找到每个员工对应的经理。
FULL JOIN
返回左表和右表中的所有行,以及两者之间匹配的行。
FULL JOIN(或 FULL OUTER JOIN)子句是 SQL 查询中用于返回左表和右表中的所有行的子句。如果没有匹配的行,结果将包含 NULL 值。
基本的 FULL JOIN 子句形式如下:
SELECT column1, column2, ...
FROM table1
FULL JOIN table2 ON table1.column_name = table2.column_name;其中:
column1, column2, ...是要选择的列的名称。table1和table2是要联结的表的名称。FULL JOIN关键字(或FULL OUTER JOIN)用于指示联结操作。ON table1.column_name = table2.column_name是指定联结条件的部分,它定义了两个表之间的关联。
例子:
SELECT employees.first_name, employees.last_name, departments.department_name
FROM employees
FULL JOIN departments ON employees.department_id = departments.department_id;在这个例子中,FULL JOIN 子句将 employees 表与 departments 表联结起来,通过 department_id 列进行关联。查询返回了员工的名字以及对应部门的名称,包括左表和右表中的所有行,即使在其中一个表中没有匹配的行,对应的员工信息或部门信息将为 NULL。
FULL JOIN 是一种保留左表和右表中的所有行的联结,即使在其中一个表中没有匹配的行也会包括在结果中。这种类型的联结通常用于需要显示两个表中的所有数据,而匹配数据是可选的情况。
需要注意的是,FULL JOIN 在一些数据库系统中可能不被支持,可以使用 LEFT JOIN 和 UNION 或 RIGHT JOIN 和 UNION 的组合来实现类似的效果。
总之,FULL JOIN 子句是 SQL 查询中用于返回左表和右表中的所有行的关键字,如果没有匹配的行,结果将包含 NULL 值。
UNION
合并两个或多个查询的结果集。
UNION 子句是 SQL 查询中用于合并两个或多个 SELECT 语句的结果集的子句。它用于将两个查询的结果组合成一个结果集,并去除重复的行。
基本的 UNION 子句形式如下:
SELECT column1, column2, ...
FROM table1
WHERE condition1
UNION
SELECT column1, column2, ...
FROM table2
WHERE condition2;其中:
column1, column2, ...是要选择的列的名称。table1和table2是要合并结果的表的名称。condition1和condition2是可选的条件,用于筛选满足特定条件的行。
需要注意的是,UNION 要求两个查询的列数和数据类型必须匹配,且结果集中会去除重复的行。如果想要包含重复的行,可以使用 UNION ALL。
例子:
SELECT first_name, last_name, salary
FROM employees
WHERE department_id = 1
UNION
SELECT first_name, last_name, salary
FROM employees
WHERE department_id = 2;在这个例子中,UNION 子句将两个查询的结果合并,返回了部门ID为1和2的员工的名字和工资,确保结果中没有重复的行。
UNION 还可以用于合并多个查询的结果,例如:
SELECT column1, column2, ...
FROM table1
WHERE condition1
UNION
SELECT column1, column2, ...
FROM table2
WHERE condition2
UNION
SELECT column1, column2, ...
FROM table3
WHERE condition3;总之,UNION 子句是 SQL 查询中用于合并两个或多个 SELECT 语句的结果集的关键字,确保结果中不包含重复的行。
UNION ALL
合并两个或多个查询的结果集,包括重复行。
UNION ALL 子句是 SQL 查询中用于合并两个或多个 SELECT 语句的结果集的子句。与 UNION 不同的是,UNION ALL 不去除重复的行,而是简单地将所有的行都包括在结果中。
基本的 UNION ALL 子句形式如下:
SELECT column1, column2, ...
FROM table1
WHERE condition1
UNION ALL
SELECT column1, column2, ...
FROM table2
WHERE condition2;其中:
column1, column2, ...是要选择的列的名称。table1和table2是要合并结果的表的名称。condition1和condition2是可选的条件,用于筛选满足特定条件的行。
与 UNION 不同,UNION ALL 不会去除重复的行,因此它的查询速度可能比 UNION 更快。然而,如果需要去重并且结果集中不包含重复的行,应该使用 UNION。
例子:
SELECT first_name, last_name, salary
FROM employees
WHERE department_id = 1
UNION ALL
SELECT first_name, last_name, salary
FROM employees
WHERE department_id = 2;在这个例子中,UNION ALL 子句将两个查询的结果合并,返回了部门ID为1和2的员工的名字和工资,包含了所有行,包括可能的重复行。
UNION ALL 还可以用于合并多个查询的结果,其语法与 UNION 类似。
总之,UNION ALL 子句是 SQL 查询中用于合并两个或多个 SELECT 语句的结果集的关键字,与 UNION 不同的是,它不去除重复的行,简单地将所有行都包括在结果中。
INTERSECT
返回两个查询的交集。
INTERSECT 子句是 SQL 查询中用于从两个查询的结果集中找到共同的行的子句。它返回同时存在于两个查询结果中的行,并去除重复的行。
基本的 INTERSECT 子句形式如下:
SELECT column1, column2, ...
FROM table1
WHERE condition1
INTERSECT
SELECT column1, column2, ...
FROM table2
WHERE condition2;其中:
column1, column2, ...是要选择的列的名称。table1和table2是要比较的表的名称。condition1和condition2是可选的条件,用于筛选满足特定条件的行。
INTERSECT 子句返回同时存在于两个查询结果中的行,并确保结果中不包含重复的行。需要注意的是,两个查询的列数和数据类型必须匹配。
例子:
SELECT first_name, last_name
FROM employees
WHERE department_id = 1
INTERSECT
SELECT first_name, last_name
FROM employees
WHERE department_id = 2;在这个例子中,INTERSECT 子句返回了既属于部门ID为1的员工又属于部门ID为2的员工的名字,确保结果中不包含重复的行。
INTERSECT 可以用于比较两个查询的结果集,找到它们的交集。它在某些情况下可以替代使用 INNER JOIN 或其他联结方式。
总之,INTERSECT 子句是 SQL 查询中用于从两个查询的结果集中找到共同的行的关键字,并确保结果中不包含重复的行。
EXCEPT
返回两个查询的差集。
EXCEPT 子句是 SQL 查询中用于从一个查询结果中排除另一个查询结果的子句。它返回只存在于第一个查询结果中而不存在于第二个查询结果中的行,并去除重复的行。
基本的 EXCEPT 子句形式如下:
SELECT column1, column2, ...
FROM table1
WHERE condition1
EXCEPT
SELECT column1, column2, ...
FROM table2
WHERE condition2;其中:
column1, column2, ...是要选择的列的名称。table1和table2是要比较的表的名称。condition1和condition2是可选的条件,用于筛选满足特定条件的行。
EXCEPT 子句返回只存在于第一个查询结果中而不存在于第二个查询结果中的行,并确保结果中不包含重复的行。需要注意的是,两个查询的列数和数据类型必须匹配。
例子:
SELECT first_name, last_name
FROM employees
WHERE department_id = 1
EXCEPT
SELECT first_name, last_name
FROM employees
WHERE department_id = 2;在这个例子中,EXCEPT 子句返回了仅属于部门ID为1的员工而不属于部门ID为2的员工的名字,确保结果中不包含重复的行。
EXCEPT 可以用于比较两个查询的结果集,找到它们的差异。它在某些情况下可以替代使用 LEFT JOIN 或其他联结方式。
总之,EXCEPT 子句是 SQL 查询中用于从一个查询结果中排除另一个查询结果的关键字,并确保结果中不包含重复的行。
FOR UPDATE 加写锁
对查询结果中的数据请求施加写锁,独占或排它锁,只有一个读和写操作
FOR UPDATE 子句是 SQL 查询中用于锁定查询结果中的行,以确保在事务中其他事务不能修改这些行。它通常用于在事务中选择要更新的行,以避免并发修改引起的问题。
基本的 FOR UPDATE 子句形式如下:
SELECT column1, column2, ...
FROM table_name
WHERE condition
FOR UPDATE;其中:
column1, column2, ...是要选择的列的名称。table_name是要查询的表的名称。condition是用于筛选行的条件。FOR UPDATE是用于锁定选定行的子句。
例子:
-- 选择部门ID为1的员工,并锁定这些行,以确保在事务中不被其他事务修改
SELECT first_name, last_name, salary
FROM employees
WHERE department_id = 1
FOR UPDATE;在这个例子中,FOR UPDATE 子句用于锁定部门ID为1的员工的行,以确保在当前事务中其他事务不能修改这些行。
需要注意的是,FOR UPDATE 子句通常在事务中使用,以避免并发更新导致的问题。在一些数据库系统中,可能还有其他形式的锁定机制,例如 FOR SHARE,它用于共享锁定而不是排他锁定。
总之,FOR UPDATE 子句是 SQL 查询中用于锁定查询结果中的行,以确保在事务中其他事务不能修改这些行。
LOCK IN SHARE MODE 加读锁
对查询结果中的数据请求施加读锁,共享锁,同时多个读操作
LOCK IN SHARE MODE 子句是 SQL 查询中用于在共享模式下锁定查询结果中的行,以确保在事务中其他事务不能以排他方式修改这些行。它通常用于在事务中选择要读取但不希望被其他事务修改的行。
基本的 LOCK IN SHARE MODE 子句形式如下:
SELECT column1, column2, ...
FROM table_name
WHERE condition
LOCK IN SHARE MODE;其中:
column1, column2, ...是要选择的列的名称。table_name是要查询的表的名称。condition是用于筛选行的条件。LOCK IN SHARE MODE是用于在共享模式下锁定选定行的子句。
例子:
-- 选择部门ID为2的员工,并以共享模式锁定这些行,以确保在事务中其他事务不能以排他方式修改这些行
SELECT first_name, last_name, salary
FROM employees
WHERE department_id = 2
LOCK IN SHARE MODE;在这个例子中,LOCK IN SHARE MODE 子句用于在共享模式下锁定部门ID为2的员工的行,以确保在当前事务中其他事务不能以排他方式修改这些行。
需要注意的是,LOCK IN SHARE MODE 子句通常在事务中使用,以避免并发更新导致的问题。它与 FOR UPDATE 子句相似,但是在锁定级别上有所不同,LOCK IN SHARE MODE 更适用于在读取数据时避免其他事务的并发写入。
总之,LOCK IN SHARE MODE 子句是 SQL 查询中用于在共享模式下锁定查询结果中的行,以确保在事务中其他事务不能以排他方式修改这些行。
多表查询
UNION 联合查询
- 两张表纵向合并,利用UNION实现
- 注意:两张表的字段必须一致 并且数据类型要相同,如第一列为学生年龄 则第二张表的第一列也要为学生年龄 否则虽然不会报错 但是逻辑上是有问题的
联合查询语法
- 默认去重,使用 UNION ALL 表示不去重
SELECT col_name1,col_name2 FROM table_name1 UNION[ALL] SELECT col_name1,col_name2 FROM table_name2 UNION[ALL] SELECT col_name1,col_name2 FROM table_name3...;联合查询范例
两张表合并
#students表内容
mysql> select * from students;
+-------+---------------+-----+--------+---------+-----------+
| StuID | Name | Age | Gender | ClassID | TeacherID |
+-------+---------------+-----+--------+---------+-----------+
| 1 | Shi Zhongyu | 22 | M | 2 | 3 |
| 2 | Shi Potian | 22 | M | 1 | 7 |
| 3 | Xie Yanke | 53 | M | 2 | 16 |
| 4 | Ding Dian | 32 | M | 4 | 4 |
| 5 | Yu Yutong | 26 | M | 3 | 1 |
| 6 | Shi Qing | 46 | M | 5 | NULL |
| 7 | Xi Ren | 19 | F | 3 | NULL |
| 8 | Lin Daiyu | 17 | F | 7 | NULL |
| 9 | Ren Yingying | 20 | F | 6 | NULL |
| 10 | Yue Lingshan | 19 | F | 3 | NULL |
| 11 | Yuan Chengzhi | 23 | M | 6 | NULL |
| 12 | Wen Qingqing | 19 | F | 1 | NULL |
| 13 | Tian Boguang | 33 | M | 2 | NULL |
| 14 | Lu Wushuang | 17 | F | 3 | NULL |
| 15 | Duan Yu | 19 | M | 4 | NULL |
| 16 | Xu Zhu | 21 | M | 1 | NULL |
| 17 | Lin Chong | 25 | M | 4 | NULL |
| 18 | Hua Rong | 23 | M | 7 | NULL |
| 19 | Xue Baochai | 18 | F | 6 | NULL |
| 20 | Diao Chan | 19 | F | 7 | NULL |
| 21 | Huang Yueying | 22 | F | 6 | NULL |
| 22 | Xiao Qiao | 20 | F | 1 | NULL |
| 23 | Ma Chao | 23 | M | 4 | NULL |
| 24 | Xu Xian | 27 | M | NULL | NULL |
| 25 | Sun Dasheng | 100 | M | NULL | NULL |
+-------+---------------+-----+--------+---------+-----------+
#teachers表内容
mysql> select * from teachers;
+-----+---------------+-----+--------+
| TID | Name | Age | Gender |
+-----+---------------+-----+--------+
| 1 | Song Jiang | 45 | M |
| 2 | Zhang Sanfeng | 94 | M |
| 3 | Miejue Shitai | 77 | F |
| 4 | Lin Chaoying | 93 | F |
+-----+---------------+-----+--------+
#两张表合并
mysql> SELECT * FROM teachers UNION SELECT stuid,name,age,gender FROM students;
+-----+---------------+-----+--------+
| TID | Name | Age | Gender |
+-----+---------------+-----+--------+
| 1 | Song Jiang | 45 | M |
| 2 | Zhang Sanfeng | 94 | M |
| 3 | Miejue Shitai | 77 | F |
| 4 | Lin Chaoying | 93 | F |
| 1 | Shi Zhongyu | 22 | M |
| 2 | Shi Potian | 22 | M |
| 3 | Xie Yanke | 53 | M |
| 4 | Ding Dian | 32 | M |
| 5 | Yu Yutong | 26 | M |
| 6 | Shi Qing | 46 | M |
| 7 | Xi Ren | 19 | F |
| 8 | Lin Daiyu | 17 | F |
| 9 | Ren Yingying | 20 | F |
| 10 | Yue Lingshan | 19 | F |
| 11 | Yuan Chengzhi | 23 | M |
| 12 | Wen Qingqing | 19 | F |
| 13 | Tian Boguang | 33 | M |
| 14 | Lu Wushuang | 17 | F |
| 15 | Duan Yu | 19 | M |
| 16 | Xu Zhu | 21 | M |
| 17 | Lin Chong | 25 | M |
| 18 | Hua Rong | 23 | M |
| 19 | Xue Baochai | 18 | F |
| 20 | Diao Chan | 19 | F |
| 21 | Huang Yueying | 22 | F |
| 22 | Xiao Qiao | 20 | F |
| 23 | Ma Chao | 23 | M |
| 24 | Xu Xian | 27 | M |
| 25 | Sun Dasheng | 100 | M |
+-----+---------------+-----+--------+去重与不去重
准备表
#基于teachers表创建teachers2表
mysql> create table teachers2 select * from teachers;
mysql> select * from teachers;
+-----+---------------+-----+--------+
| TID | Name | Age | Gender |
+-----+---------------+-----+--------+
| 1 | Song Jiang | 45 | M |
| 2 | Zhang Sanfeng | 94 | M |
| 3 | Miejue Shitai | 77 | F |
| 4 | Lin Chaoying | 93 | F |
+-----+---------------+-----+--------+
mysql> select * from teachers2;
+-----+---------------+-----+--------+
| TID | Name | Age | Gender |
+-----+---------------+-----+--------+
| 1 | Song Jiang | 45 | M |
| 2 | Zhang Sanfeng | 94 | M |
| 3 | Miejue Shitai | 77 | F |
| 4 | Lin Chaoying | 93 | F |
+-----+---------------+-----+--------+去重
- UNION 默认就是去重的
mysql> select * from teachers UNION select * from teachers2;
+-----+---------------+-----+--------+
| TID | Name | Age | Gender |
+-----+---------------+-----+--------+
| 1 | Song Jiang | 45 | M |
| 2 | Zhang Sanfeng | 94 | M |
| 3 | Miejue Shitai | 77 | F |
| 4 | Lin Chaoying | 93 | F |
+-----+---------------+-----+--------+不去重
- UNION ALL 表示不去重
mysql> select * from teachers UNION ALL select * from teachers2;
+-----+---------------+-----+--------+
| TID | Name | Age | Gender |
+-----+---------------+-----+--------+
| 1 | Song Jiang | 45 | M |
| 2 | Zhang Sanfeng | 94 | M |
| 3 | Miejue Shitai | 77 | F |
| 4 | Lin Chaoying | 93 | F |
| 1 | Song Jiang | 45 | M |
| 2 | Zhang Sanfeng | 94 | M |
| 3 | Miejue Shitai | 77 | F |
| 4 | Lin Chaoying | 93 | F |
+-----+---------------+-----+--------+INNER JOIN 内连接
- 取A表和B表的交集
- 使用 INNER JOIN 实现
内连接语法
SELECT <select_list> FROM TableA A INNER JOIN TableB B ON A.Key=B.Key内连接范例
- 过滤出 students表中TeacherID 和 teachers表中tid相同的内容
#语法1
select * from students INNER JOIN teachers ON students.TeacherID=teachers.tid;
#语法2,起别名
select * from students s INNER JOIN teachers t ON s.TeacherID=t.tid;
#再过滤需要的字段并起别名
select s.name 学生姓名,s.age 学生年龄,s.gender 学生性别,t.name 老师姓名,t.age 老师年龄,t.gender 老师性别 from students s INNER JOIN teachers t ON s.TeacherID=t.tid;
#在上面的基础上,再过滤掉年龄超过50的老师
#方法一,使用where,表示在前面显示的基础上只显示年龄小于50的老师,WHERE表示前面的数据处理完,在处理WHERE后面的
select s.name 学生姓名,s.age 学生年龄,s.gender 学生性别,t.name 老师姓名,t.age 老师年龄,t.gender
老师性别 from students s INNER JOIN teachers t ON s.TeacherID=t.tid where t.age<50;
#方法二,使用and,s.TeacherID 等于 t.tid 并且 t.age<50,并且的关系,AND表示将前面的内容作为一个整体来处理
select s.name 学生姓名,s.age 学生年龄,s.gender 学生性别,t.name 老师姓名,t.age 老师年龄,t.gender
老师性别 from students s INNER JOIN teachers t ON s.TeacherID=t.tid and t.age<50;- 过滤出 students表中gender 和 teachers表中的gender 不相同的内容,即男学生对应女老师,女学生对应男老师
#语法1
#使用!=,非标准SQL
select * from students INNER JOIN teachers ON students.gender!=teachers.gender;
#使用<>
select * from students INNER JOIN teachers ON students.gender<>teachers.gender;
#语法2,起别名
select * from students s INNER JOIN teachers t ON s.gender!=t.gender;
#或
select * from students s INNER JOIN teachers t ON s.gender<>t.gender;
#再过滤需要的字段并起别名
select s.name 学生姓名,s.age 学生年龄,s.gender 学生性别,t.name 老师姓名,t.age 老师年龄,t.gender 老师性别 from students s INNER JOIN teachers t ON s.gender<>t.gender;
#在上面的基础上,再过滤掉年龄超过50的老师
#方法一,使用where,表示在前面显示的基础上只显示年龄小于50的老师,WHERE表示前面的数据处理完,在处理WHERE后面的
select s.name 学生姓名,s.age 学生年龄,s.gender 学生性别,t.name 老师姓名,t.age 老师年龄,t.gender 老师性别 from students s INNER JOIN teachers t ON s.gender<>t.gender where t.age<50;
#方法二,使用and,s.TeacherID 等于 t.tid 并且 t.age<50,并且的关系,AND表示将前面的内容作为一个整体来处理
select s.name 学生姓名,s.age 学生年龄,s.gender 学生性别,t.name 老师姓名,t.age 老师年龄,t.gender 老师性别 from students s INNER JOIN teachers t ON s.gender<>t.gender and t.age<50;FULL OUTER JOIN 完全外连接
取两张或多张表的全部内容
完全外连接语法
- 注意:MySQL不支持FULL OUTER JOIN语法,其他的数据库支持
SELECT <select_list> FROM TableA A FULL OUTER JOIN TableB B ON A.Key=B.Key- MySQL支持的语法,利用 LEFT JOIN + UNION + RIGHT JOIN 实现,并且因为UNION默认是去重的 所以无需担心重复的问题
SELECT <select_list> FROM TableA A LEFT [OUTER] JOIN TableB B ON A.Key=B.Key UNION SELECT <select_list> FROM TableA A RIGHT [OUTER] JOIN TableB B ON A.Key=B.Key完全外连接范例
select * from students s left join teachers t on s.teacherid=t.tid union select * from students s right join teachers t on s.teacherid=t.tid;
#加上ALL会显示的更直观,但是不会去重了
select * from students s left join teachers t on s.teacherid=t.tid union all select * from students s right join teachers t on s.teacherid=t.tid;实现完全外连接去除交集
语法
- 左外连接扩展 UNION 右外连接扩展 即可实现
select * from students s left join teachers t on s.teacherid=t.tid where tid is null UNION select * from students s RIGHT JOIN teachers t on s.teacherid=t.tid where teacherid is null;三表查询
三表查询范例
- 查询出学生的考试科目以及成绩
- 注意:因为学生表和考试科目表没有直接的联系,所以只能先通过学生表和成绩表查出学生对应的考试成绩,最后再将成绩表和课程表关联查出学生的考试科目以及成绩
现有表
students
- 学生表
mysql> select * from students;
+-------+---------------+-----+--------+---------+-----------+
| StuID | Name | Age | Gender | ClassID | TeacherID |
+-------+---------------+-----+--------+---------+-----------+
| 1 | Shi Zhongyu | 22 | M | 2 | 3 |
| 2 | Shi Potian | 22 | M | 1 | 7 |
| 3 | Xie Yanke | 53 | M | 2 | 16 |
| 4 | Ding Dian | 32 | M | 4 | 4 |
| 5 | Yu Yutong | 26 | M | 3 | 1 |
| 6 | Shi Qing | 46 | M | 5 | NULL |
| 7 | Xi Ren | 19 | F | 3 | NULL |
| 8 | Lin Daiyu | 17 | F | 7 | NULL |
| 9 | Ren Yingying | 20 | F | 6 | NULL |
| 10 | Yue Lingshan | 19 | F | 3 | NULL |
| 11 | Yuan Chengzhi | 23 | M | 6 | NULL |
| 12 | Wen Qingqing | 19 | F | 1 | NULL |
| 13 | Tian Boguang | 33 | M | 2 | NULL |
| 14 | Lu Wushuang | 17 | F | 3 | NULL |
| 15 | Duan Yu | 19 | M | 4 | NULL |
| 16 | Xu Zhu | 21 | M | 1 | NULL |
| 17 | Lin Chong | 25 | M | 4 | NULL |
| 18 | Hua Rong | 23 | M | 7 | NULL |
| 19 | Xue Baochai | 18 | F | 6 | NULL |
| 20 | Diao Chan | 19 | F | 7 | NULL |
| 21 | Huang Yueying | 22 | F | 6 | NULL |
| 22 | Xiao Qiao | 20 | F | 1 | NULL |
| 23 | Ma Chao | 23 | M | 4 | NULL |
| 24 | Xu Xian | 27 | M | NULL | NULL |
| 25 | Sun Dasheng | 100 | M | NULL | NULL |
+-------+---------------+-----+--------+---------+-----------+
25 rows in set (0.00 sec)
mysql> desc students;
+-----------+------------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-----------+------------------+------+-----+---------+----------------+
| StuID | int unsigned | NO | PRI | NULL | auto_increment |
| Name | varchar(50) | NO | | NULL | |
| Age | tinyint unsigned | NO | | NULL | |
| Gender | enum('F','M') | NO | | NULL | |
| ClassID | tinyint unsigned | YES | | NULL | |
| TeacherID | int unsigned | YES | | NULL | |
+-----------+------------------+------+-----+---------+----------------+
6 rows in set (0.00 sec)courses
- 课程表
mysql> select * from courses;
+----------+----------------+
| CourseID | Course |
+----------+----------------+
| 1 | Hamo Gong |
| 2 | Kuihua Baodian |
| 3 | Jinshe Jianfa |
| 4 | Taiji Quan |
| 5 | Daiyu Zanghua |
| 6 | Weituo Zhang |
| 7 | Dagou Bangfa |
+----------+----------------+
7 rows in set (0.00 sec)
mysql> desc courses;
+----------+-------------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+----------+-------------------+------+-----+---------+----------------+
| CourseID | smallint unsigned | NO | PRI | NULL | auto_increment |
| Course | varchar(100) | NO | | NULL | |
+----------+-------------------+------+-----+---------+----------------+
2 rows in set (0.00 sec)scores
- 考试成绩表
- 这里的StuID 和 CourseID应该以作为外键表的方式分别指向 student表的StuID 和 classes表的ClassID,否则有可能会出现数据输入超出范围从而导致查询错误的问题
mysql> select * from scores;
+----+-------+----------+-------+
| ID | StuID | CourseID | Score |
+----+-------+----------+-------+
| 1 | 1 | 2 | 77 |
| 2 | 1 | 6 | 93 |
| 3 | 2 | 2 | 47 |
| 4 | 2 | 5 | 97 |
| 5 | 3 | 2 | 88 |
| 6 | 3 | 6 | 75 |
| 7 | 4 | 5 | 71 |
| 8 | 4 | 2 | 89 |
| 9 | 5 | 1 | 39 |
| 10 | 5 | 7 | 63 |
| 11 | 6 | 1 | 96 |
| 12 | 7 | 1 | 86 |
| 13 | 7 | 7 | 83 |
| 14 | 8 | 4 | 57 |
| 15 | 8 | 3 | 93 |
+----+-------+----------+-------+
15 rows in set (0.01 sec)
mysql> desc scores;
+----------+-------------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+----------+-------------------+------+-----+---------+----------------+
| ID | int unsigned | NO | PRI | NULL | auto_increment |
| StuID | int unsigned | NO | | NULL | |
| CourseID | smallint unsigned | NO | | NULL | |
| Score | tinyint unsigned | YES | | NULL | |
+----------+-------------------+------+-----+---------+----------------+
4 rows in set (0.00 sec)通过两张表查询每个学生的考试成绩
-
使用 scores表 和 students表
-
只能使用 INNER JOIN,因为使用LEFT JOIN 或 RIGHT JOIN的话有可能会出现学生无对应课程的情况 因此会出现为NULL的行
mysql> select st.name 学生姓名,sc.score 考试成绩 from students st INNER JOIN scores sc ON sc.stuid=st.stuid;
+--------------+--------------+
| 学生姓名 | 考试成绩 |
+--------------+--------------+
| Shi Zhongyu | 77 |
| Shi Zhongyu | 93 |
| Shi Potian | 47 |
| Shi Potian | 97 |
| Xie Yanke | 88 |
| Xie Yanke | 75 |
| Ding Dian | 71 |
| Ding Dian | 89 |
| Yu Yutong | 39 |
| Yu Yutong | 63 |
| Shi Qing | 96 |
| Xi Ren | 86 |
| Xi Ren | 83 |
| Lin Daiyu | 57 |
| Lin Daiyu | 93 |
+--------------+--------------+
#或者
mysql> select st.name 学生姓名,sc.CourseID 课程ID,sc.Score 考试成绩 from students st inner join scores sc on st.stuid=sc.stuid;
+--------------+----------+--------------+
| 学生姓名 | 课程ID | 考试成绩 |
+--------------+----------+--------------+
| Shi Zhongyu | 2 | 77 |
| Shi Zhongyu | 6 | 93 |
| Shi Potian | 2 | 47 |
| Shi Potian | 5 | 97 |
| Xie Yanke | 2 | 88 |
| Xie Yanke | 6 | 75 |
| Ding Dian | 5 | 71 |
| Ding Dian | 2 | 89 |
| Yu Yutong | 1 | 39 |
| Yu Yutong | 7 | 63 |
| Shi Qing | 1 | 96 |
| Xi Ren | 1 | 86 |
| Xi Ren | 7 | 83 |
| Lin Daiyu | 4 | 57 |
| Lin Daiyu | 3 | 93 |
+--------------+----------+--------------+通过三张表查询每个学生上的课程以及分数
- 在上面两张表查询的基础上添加第三张表进行查询
mysql> select st.name 学生姓名,co.Course 考试科目,sc.score 考试成绩 from students st INNER JOIN scores sc ON sc.stuid=st.stuid INNER JOIN courses co ON co.CourseID=sc.CourseID;
+--------------+----------------+--------------+
| 学生姓名 | 考试科目 | 考试成绩 |
+--------------+----------------+--------------+
| Shi Zhongyu | Kuihua Baodian | 77 |
| Shi Zhongyu | Weituo Zhang | 93 |
| Shi Potian | Kuihua Baodian | 47 |
| Shi Potian | Daiyu Zanghua | 97 |
| Xie Yanke | Kuihua Baodian | 88 |
| Xie Yanke | Weituo Zhang | 75 |
| Ding Dian | Daiyu Zanghua | 71 |
| Ding Dian | Kuihua Baodian | 89 |
| Yu Yutong | Hamo Gong | 39 |
| Yu Yutong | Dagou Bangfa | 63 |
| Shi Qing | Hamo Gong | 96 |
| Xi Ren | Hamo Gong | 86 |
| Xi Ren | Dagou Bangfa | 83 |
| Lin Daiyu | Taiji Quan | 57 |
| Lin Daiyu | Jinshe Jianfa | 93 |
+--------------+----------------+--------------+
15 rows in set (0.00 sec)SELECT 语句执行顺序
FROM --> WHERE --> GROUP BY --> HAVING -->SELECT --> DISTINCT --> ORDER BY --> LIMIT在 SQL 中,SELECT 语句的执行顺序通常如下:
-
FROM 子句: 查询从 FROM 子句开始。在这一步,确定要从哪个表或表的组合中检索数据。
-
WHERE 子句: 如果查询包含 WHERE 子句,则在执行其他操作之前,首先将应用 WHERE 子句中的过滤条件。这会筛选出符合条件的行。
-
GROUP BY 子句: 如果查询包含 GROUP BY 子句,则将根据 GROUP BY 子句中指定的列对结果进行分组。这一步将数据按照指定的分组进行聚合。
-
HAVING 子句: 如果查询包含 HAVING 子句,则在应用 GROUP BY 子句后,HAVING 子句中的条件将用于筛选分组。只有符合条件的分组才会被包含在结果集中。
-
SELECT 子句: 在这一步,执行 SELECT 子句中指定的列的计算或选择操作。这些列可能是表中的原始列,也可能是聚合函数的结果,或者是其他计算字段。
-
DISTINCT 关键字: 如果查询中包含 DISTINCT 关键字,则在 SELECT 子句的结果集上应用去重操作。
-
ORDER BY 子句: 如果查询包含 ORDER BY 子句,则对结果集按照指定的列进行排序。这一步是在其他操作执行之后进行的。
-
LIMIT 子句: 最后,如果查询包含 LIMIT 子句,则应用 LIMIT 子句以限制结果集中返回的行数。
需要注意的是,尽管以上步骤给出了一般的 SELECT 语句执行顺序,但是数据库优化器可能会对查询进行重写或重组,以提高查询性能。因此,实际执行的顺序可能会有所不同,取决于查询的具体内容以及数据库管理系统的优化策略。
示例1
-- 由于 SELECT 后于 WHERE 执行,因此无法在 WHERE 中使用 SELECT 定义的别名 a。
mysql> SELECT age as a FROM students WHERE a=22;
ERROR 1054 (42S22): Unknown column 'a' in 'where clause'
-- 由于 FROM 先于 WHERE 执行,因此可以在 WHERE 中使用 FROM 定义的别名 stu。
mysql> SELECT age FROM students as stu WHERE stu.age=22;
+-----+
| age |
+-----+
| 22 |
| 22 |
| 22 |
+-----+其他
查询执行路径中的组件:查询缓存、解析器、预处理器、优化器、查询执行引擎、存储引擎
这句话描述了 SQL 查询在执行过程中经过的关键组件,它们的作用如下:
-
查询缓存(Query Cache): 当查询被执行时,数据库管理系统首先会检查查询缓存,看是否存在之前执行过的相同查询的缓存结果。如果存在并且查询条件没有变化,数据库系统可以直接返回缓存结果,而无需重新执行查询。
-
解析器(Parser): 解析器负责解析 SQL 查询语句,将其转换为数据库内部的数据结构。解析器检查语法错误,并确定查询的语义。
-
预处理器(Preprocessor): 预处理器进一步处理解析后的查询语句,可能会进行一些语义检查、权限检查等操作,以确保用户有权限执行该查询。
-
优化器(Optimizer): 优化器负责对查询进行优化,以提高查询执行的性能。它会根据查询的复杂度、表的大小、索引情况等因素来生成一个最优的执行计划。优化器可能会考虑多种执行策略,并选择其中最有效的策略。
-
查询执行引擎(Query Execution Engine): 查询执行引擎根据优化器生成的执行计划,实际执行查询并获取结果。它负责管理查询的执行过程,包括读取数据、执行计算、应用过滤条件等操作。
-
存储引擎(Storage Engine): 存储引擎负责管理数据的存储和检索。它负责将查询的结果从磁盘读取到内存中,并且提供了对数据的基本操作,如插入、更新、删除等。存储引擎也负责处理锁和事务等数据库操作的并发控制问题。
综合起来,这些组件共同协作,完成了 SQL 查询的执行过程,从查询解析到最终结果返回。优化器和存储引擎通常是影响查询性能的重要因素,它们的选择和配置可以对查询执行速度产生显著影响。
EXPLAIN
mysql> EXPLAIN SELECT sum(age) FROM teachers;
+----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+-------+
| 1 | SIMPLE | teachers | NULL | ALL | NULL | NULL | NULL | NULL | 4 | 100.00 | NULL |
+----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+-------+
1 row in set, 1 warning (0.01 sec)EXPLAIN 是一个 SQL 命令,用于分析查询语句的执行计划,从而帮助优化查询性能。通过执行 EXPLAIN 命令可以获取关于查询执行的各种信息,包括表访问顺序、索引使用情况、执行策略等,进而可以根据这些信息进行优化。
以下是使用 EXPLAIN 命令的基本语法:
EXPLAIN SELECT column1, column2, ...
FROM table_name
WHERE condition;执行上述命令后,数据库管理系统会返回一个执行计划的结果集,其中包含了关于查询执行的各种信息。下面是一些常见的执行计划中的字段以及它们的含义:
- id: 查询执行步骤的编号,从 1 开始递增。
- select_type: 查询类型,表示查询的类型,例如简单查询、联合查询、子查询等。
- table: 表名,表示查询涉及的表。
- type: 访问类型,表示访问表的方式,例如全表扫描、索引扫描、范围扫描等。
- possible_keys: 可能使用的索引,表示查询的潜在索引。
- key: 实际使用的索引,表示查询实际使用的索引。
- key_len: 使用的索引长度,表示索引字段的长度。
- ref: 表示查询中索引的匹配条件。
- rows: 估计的行数,表示查询返回的行数。
- Extra: 额外信息,包含了一些额外的执行信息,例如使用了临时表、使用了文件排序等。
通过分析 EXPLAIN 的执行计划,可以发现查询的瓶颈和潜在的性能优化点,进而根据具体情况进行优化。例如,可以通过添加合适的索引、重写查询语句、优化 SQL 语句结构等方式来提高查询性能。
需要注意的是,EXPLAIN 只是一个分析工具,它提供了查询执行的一些统计信息,但并不会真正执行查询。因此,执行计划中的实际行为可能与执行结果略有不同,需要根据实际情况进行综合考虑。
假设我们有一个简单的表 employees,包含以下字段:
employee_id:员工ID,主键name:员工姓名age:员工年龄department_id:部门ID
现在我们想要查询所有年龄大于 30 岁的员工信息,并且按照部门ID进行排序。我们可以使用 EXPLAIN 命令来分析这个查询语句的执行计划,看看是否有优化的空间。
首先,让我们创建这个示例表 employees 并插入一些数据:
CREATE TABLE employees (
employee_id INT PRIMARY KEY,
name VARCHAR(50),
age INT,
department_id INT
);
INSERT INTO employees (employee_id, name, age, department_id) VALUES
(1, 'Alice', 25, 101),
(2, 'Bob', 35, 102),
(3, 'Charlie', 30, 101),
(4, 'David', 40, 103),
(5, 'Eve', 28, 102);然后,我们执行查询并使用 EXPLAIN 命令来分析查询的执行计划:
EXPLAIN SELECT * FROM employees WHERE age > 30 ORDER BY department_id;执行以上查询后,数据库会返回一个执行计划,类似于下面的结果:
+----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+---------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+---------------------------------+
| 1 | SIMPLE | employees | NULL | ALL | NULL | NULL | NULL | NULL | 5 | 100.00 | Using where; Using filesort |
+----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+---------------------------------+这个执行计划告诉我们:
- 查询使用了
employees表。 - 执行了全表扫描 (
type: ALL),没有使用到索引。 - 表中有 5 行数据,全部都需要被扫描。
- 查询使用了
WHERE子句进行过滤,并且使用了文件排序 (Using where; Using filesort) 来进行ORDER BY操作。
根据这个执行计划,我们可以看到全表扫描可能会影响查询性能,因为即使表中只有少量数据,数据库也需要扫描整个表来找到符合条件的行。为了优化这个查询,我们可以考虑添加一个合适的索引,例如在 age 字段上添加一个索引,以便数据库可以更快地找到符合条件的行。
CREATE INDEX idx_age ON employees (age);然后再次执行查询并分析执行计划,看看是否有所改善。